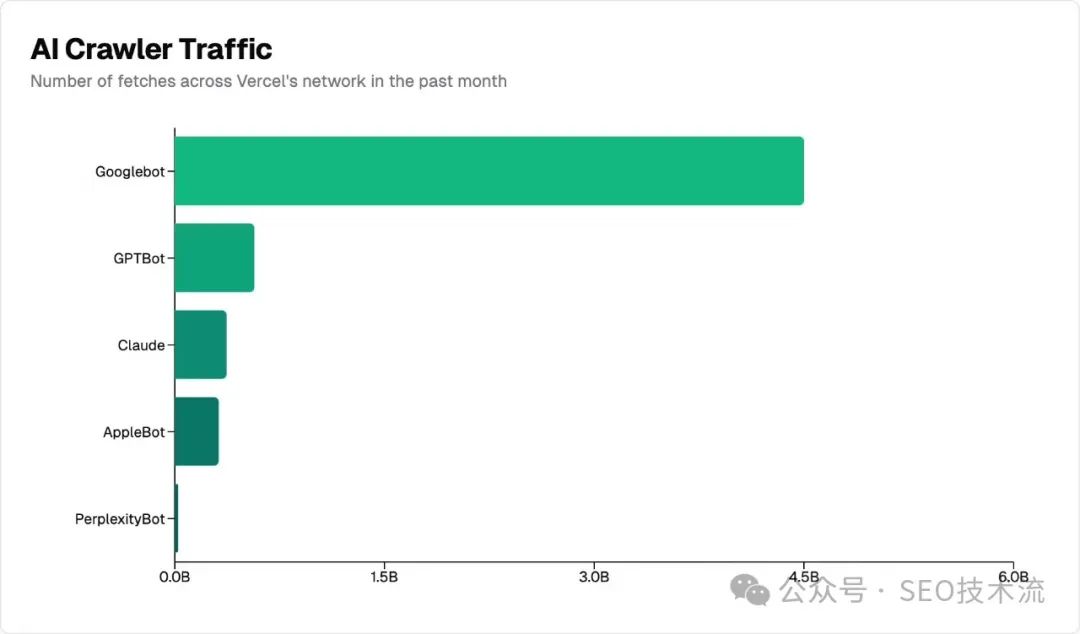
本文是 MERJ 和 Vercel 研究實(shí)際數(shù)據(jù)總結(jié)了目前主流 AI 爬蟲的幾個(gè)特征。 注:Vercel 是 Next.js 的前端云平臺(tái);MERJ 是數(shù)據(jù)驅(qū)動(dòng)的營(yíng)銷公司;本文翻譯自 Vercel 的 Blog 文章《The rise of the AI crawler》。 整體上,AI 爬蟲已經(jīng)成為網(wǎng)絡(luò)上的重要存在。在過去一個(gè)月中,OpenAI 的 GPTBot 在 Vercel 網(wǎng)絡(luò)上產(chǎn)生了 5.69 億次抓取,而 Anthropic 的 Claude 緊隨其后,達(dá)到了 3.7 億次。 而這 2 個(gè)加起來的請(qǐng)求量只占同期 Googlebot 45 億次抓取的 20%。 Vercel 網(wǎng)絡(luò)上的 AI 爬蟲流量非常大。在過去的一個(gè)月: GPTBot、Claude、AppleBot 和 PerplexityBot 合計(jì)抓取了近 13 億次,約占 Googlebot 總抓取量的 28%+。 雖然AI 爬蟲尚未達(dá)到 Googlebot 的規(guī)模,但他們已占據(jù)網(wǎng)絡(luò)爬蟲流量的很大部分。 這些 AI 爬蟲都在美國(guó)數(shù)據(jù)中心: 相比之下,傳統(tǒng)搜索引擎通常會(huì)將抓取分散到多個(gè)地區(qū)。例如,Googlebot 在美國(guó)七個(gè)不同的地區(qū)運(yùn)營(yíng),包括達(dá)爾斯(俄勒岡州)、康瑟爾布拉夫斯(愛荷華州)和蒙克斯科納(南卡羅來納州)。 AI 爬蟲在 JavaScript 渲染能力方面存在明顯差異。為了驗(yàn)證我們的發(fā)現(xiàn),我們分析了使用不同技術(shù)棧的 Next.js 應(yīng)用程序和傳統(tǒng)網(wǎng)頁應(yīng)用。 調(diào)查結(jié)果一致表明,目前主要的 AI 爬蟲都不渲染 JavaScript。這包括: 研究結(jié)果還顯示: 數(shù)據(jù)表明,雖然 ChatGPT 和 Claude 的爬蟲確實(shí)會(huì)獲取 JavaScript 文件(ChatGPT:11.50%,Claude:23.84% 的請(qǐng)求),但它們并不執(zhí)行這些文件。它們無法讀取客戶端渲染的內(nèi)容。 但請(qǐng)注意,包含在初始 HTML 響應(yīng)中的內(nèi)容(如 JSON 數(shù)據(jù)或延遲的 React Server Components)可能仍會(huì)被索引,因?yàn)?AI 模型可以解析非HTML內(nèi)容。 相比之下,Gemini 使用 Google 的基礎(chǔ)設(shè)施,使其具有與我們?cè)?Googlebot 分析中記錄的相同渲染能力,能夠完整處理最新的網(wǎng)頁應(yīng)用。 AI 爬蟲在抓取 nextjs.org 時(shí)表現(xiàn)出明顯的內(nèi)容類型偏好。最明顯的特征有: 作為對(duì)比,Googlebot 的抓取量(包括 Gemini 和搜索)分布更加均勻: 這些模式表明AI 爬蟲會(huì)收集多樣化的內(nèi)容類型——HTML、圖片,甚至將 JavaScript 文件作為文本收集——這可能是為了訓(xùn)練他們的模型以適應(yīng)各種形式的網(wǎng)頁內(nèi)容。 雖然像 Google 這樣的傳統(tǒng)搜索引擎已經(jīng)針對(duì)搜索索引優(yōu)化了他們的抓取模式,但較新的AI 公司可能仍在完善他們的內(nèi)容優(yōu)先級(jí)策略。 我們的數(shù)據(jù)顯示AI 爬蟲行為存在明顯的低效現(xiàn)象: 對(duì) 404 錯(cuò)誤的分析顯示,除去 robots.txt 之外,這些爬蟲經(jīng)常嘗試獲取 /static/ 文件夾中的過期資源。這表明AI 爬蟲需要改進(jìn) URL 選擇和處理策略以避免不必要的抓取。 這些高比例的 404 錯(cuò)誤和重定向與 Googlebot 形成鮮明對(duì)比 -Googlebot 僅有 8.22% 的請(qǐng)求遇到 404 錯(cuò)誤,1.49% 的請(qǐng)求遇到重定向。這表明 Google 在優(yōu)化其爬蟲以抓取真實(shí)資源方面確實(shí)有更多經(jīng)驗(yàn)。 我們對(duì)流量模式的分析揭示了爬蟲行為和網(wǎng)站流量之間存在關(guān)聯(lián)性。基于來自 雖然傳統(tǒng)搜索引擎已經(jīng)開發(fā)出復(fù)雜的優(yōu)先級(jí)算法,但 AI 爬蟲似乎仍在不斷發(fā)展其網(wǎng)絡(luò)內(nèi)容發(fā)現(xiàn)方法。 優(yōu)先對(duì)關(guān)鍵內(nèi)容進(jìn)行服務(wù)器端渲染。?ChatGPT 和 Claude 不執(zhí)行 JavaScript,因此任何重要內(nèi)容都應(yīng)該在服務(wù)器端渲染。這包括主要內(nèi)容(文章、產(chǎn)品信息、文檔)、元信息(標(biāo)題、描述、分類)和導(dǎo)航結(jié)構(gòu)。SSR、ISR 和 SSG 能確保您的內(nèi)容對(duì)所有爬蟲都是可訪問的。 客戶端渲染仍適用于增強(qiáng)功能。?您可以放心地對(duì)非核心的動(dòng)態(tài)元素使用客戶端渲染,比如訪問計(jì)數(shù)器、交互式UI增強(qiáng)功能、在線聊天小部件和社交媒體信息流。 高效的URL管理比以往任何時(shí)候都更重要。?AI 爬蟲的高 404 錯(cuò)誤率突顯了維護(hù)適當(dāng)重定向、保持站點(diǎn)地圖更新以及在整個(gè)網(wǎng)站使用一致的 URL 模式的重要性。 使用 使用 Vercel 的 WAF 來阻止AI爬蟲。?我們的"阻止AI機(jī)器人防火墻規(guī)則"讓您只需一鍵就能阻止AI爬蟲。這個(gè)規(guī)則會(huì)自動(dòng)配置您的防火墻以拒絕它們的訪問。 JavaScript 渲染的內(nèi)容可能缺失。?由于 ChatGPT 和 Claude 不執(zhí)行 JavaScript,它們對(duì)動(dòng)態(tài)網(wǎng)絡(luò)應(yīng)用的響應(yīng)可能不完整或過時(shí)。 注意信息來源。?較高的404錯(cuò)誤率(>34%)意味著當(dāng) AI 工具引用特定網(wǎng)頁時(shí),這些 URL 很可能是錯(cuò)誤的或無法訪問的。對(duì)于重要信息,始終直接驗(yàn)證來源而不是依賴AI提供的鏈接。 預(yù)期更新的不一致性。?雖然 Gemini 利用 Google 的基礎(chǔ)設(shè)施進(jìn)行抓取,但其他 AI 助手顯示出較不可預(yù)測(cè)的模式。有些可能引用較舊的緩存數(shù)據(jù)。 有趣的是,即使在向 Claude 或 ChatGPT 請(qǐng)求最新的Next.js文檔數(shù)據(jù)時(shí),我們通常在 我們的分析顯示,AI 爬蟲已經(jīng)迅速成為網(wǎng)絡(luò)上的重要存在,在 Vercel 的網(wǎng)絡(luò)上每月有近 10 億次請(qǐng)求。 然而,在渲染能力、內(nèi)容優(yōu)先級(jí)和效率方面,它們的行為與傳統(tǒng)搜索引擎有明顯不同。遵循已建立的網(wǎng)絡(luò)開發(fā)最佳實(shí)踐——特別是在內(nèi)容可訪問性方面——仍然至關(guān)重要。
規(guī)模和分布
爬蟲位置分布
JavaScript 渲染能力
內(nèi)容類型優(yōu)先級(jí)
爬蟲效率問題
流量相關(guān)性分析
nextjs.org?的數(shù)據(jù):
建議
對(duì)于希望被抓取的網(wǎng)站站長(zhǎng)
對(duì)于不希望被抓取的網(wǎng)站所有者
robots.txt?來控制爬蟲訪問。robots.txt?文件對(duì)所有爬蟲都有效。通過指定AI爬蟲的用戶代理(user agent)或產(chǎn)品標(biāo)識(shí)(product token)來設(shè)置具體規(guī)則,以限制對(duì)敏感或非必要內(nèi)容的訪問。要找到需要禁止的用戶代理,您需要查看每個(gè)公司自己的文檔(例如,Applebot和OpenAI的爬蟲)。
對(duì)于 AI 用戶
nextjs.org?的服務(wù)器日志中也看不到即時(shí)的獲取請(qǐng)求。這表明AI模型可能依賴于緩存數(shù)據(jù)或訓(xùn)練數(shù)據(jù),即使它們聲稱已獲取最新信息。
總結(jié)
備注
文章為作者獨(dú)立觀點(diǎn),不代表DLZ123立場(chǎng)。如有侵權(quán),請(qǐng)聯(lián)系我們。( 版權(quán)為作者所有,如需轉(zhuǎn)載,請(qǐng)聯(lián)系作者 )

網(wǎng)站運(yùn)營(yíng)至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個(gè)互相交流的平臺(tái)和資源的對(duì)接,特地開通了獨(dú)立站交流群。
群里有不少運(yùn)營(yíng)大神,不時(shí)會(huì)分享一些運(yùn)營(yíng)技巧,更有一些資源收藏愛好者不時(shí)分享一些優(yōu)質(zhì)的學(xué)習(xí)資料。
現(xiàn)在可以掃碼進(jìn)群,備注【加群】。 ( 群完全免費(fèi),不廣告不賣課!)






