在 SEO 工作,我總是發現自己在仔細研究數據并尋找加快分析過程的方法。分析數據通常是乏味、頭腦麻木和無聊的工作,因此任何可以加快在大海撈針中找到針頭的方法幾乎總是一個好主意。
如果你花時間學習這些EXCEL公式,我保證這將是值得的——你可以輕松地處理 Excel 中的數千(或更多)行,廢話不多說,給大家介紹一下:
公式1
=if(isnumber(search("string 1", [beginning cell])),"Category 1", if(isnumber(search("string 2", [beginning cell])),"Category 2", "Other" )
如果我已經讓你感到困惑,我深表歉意。我將更深入地研究該公式,解釋其含義并提供 3 個不同的用例,說明它如何幫助你加快工作速度。
用例 1:關鍵字研究
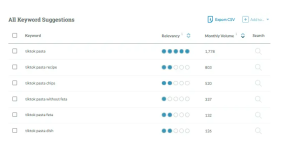
當做關鍵字研究時,可能你有數千行的數據需要研究搜索量,嘗試將相似的關鍵字放在一起以查看相似性,進行關鍵詞分類是SEO的基本工作,那么如何快速對關鍵詞進行分類呢?
如果你想分解整個列表(681 行數據,顯然都沒有顯示在屏幕截圖中)以找出有多少查詢包含“supplement”這個詞,或者你想知道有多少包含“muscle”。在單元格 C2 中,我們將鍵入公式:
=if(isnumber(search("supplement",A2)),"Supplement", if(isnumber(search("muscle",A2)),"Muscle","Other"))
翻譯后,此公式表示:搜索單元格 A2,如果找到“supplement”,則返回類別“supplement”。如果未找到“supplement”,則查找“muscle”,如果找到,則返回“muscle”作為類別。如果既沒有找到“muscle”也沒有找到“muscle”,則返回“other”作為類別。
我可以繼續在公式中添加我認為合適的規格.下面的屏幕截圖顯示了這個公式的作用:
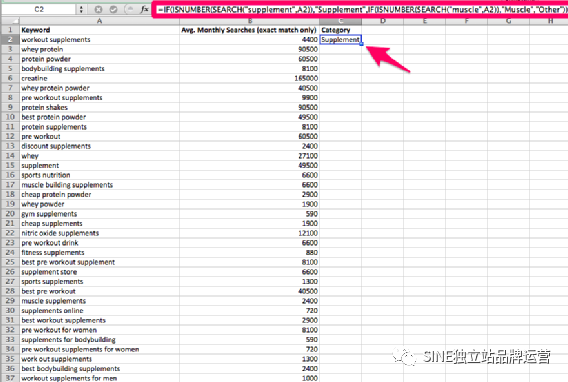
這個公式的真正威力在于它可以在整個數據集上使用,無需有人手動瀏覽和分類每個關鍵字。雙擊單元格 C2 的右下角會將公式應用于 C 列中的所有單元格,只要 B 列中它旁邊有一個值(這是 Excel 的規則) ,不是公式)。下面的屏幕截圖顯示了將公式應用于所有數據的效果。請注意公式如何從分析單元格 A2 更改為單元格 C19 中的單元格 A19,其中應用了該公式。
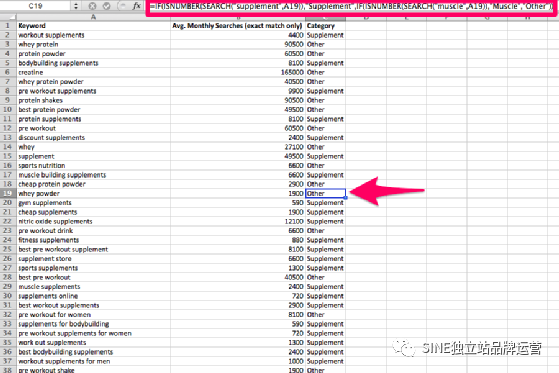
“muscle”未在屏幕截圖中列為類別,但在數據集中稍后列為類別。在這一點上,我還需要指出公式中的一個不足之處。如果特定查詢包含多個我們嘗試分類的字符串,它將返回它找到的第一個正字符串匹配的類別。第 29 行就是一個很好的例子。在此特定場景中,查詢是“supplement”,但由于公式在查找“muscle”之前先查找“supplement”?,并且在“supplement”中找到了正匹配,因此它將單元格歸類為“supplement”。
在既沒有找到“supplement”也沒有找到“muscle”的單元格中,它返回“other”。此時,我們向數據集添加了一個過濾器,可以過濾掉所有“muscle”和“supplement”查詢,以準確揭示“other”的組成部分。

查看此列表,包含“protein”的查詢似乎占列表的相當大的百分比,因此我們也可以將其添加為一個類別。從這里我們可以添加一個數據透視表并按搜索量和關鍵字數量進行排序。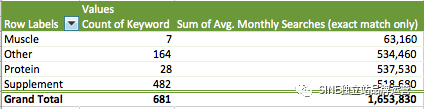
從這里我們可以了解我們應該將努力的目標定位于何處以及我們需要更多關注的地方。在這一點上,“other”仍然是一個太大的類別,所以我會進一步細化它以創建更多類別,以找出我們如何使其更具可操作性。
用例 #2:拒絕垃圾外鏈
根據你站點的大小,你可能會處理數千或數百萬個外鏈跟域名,因此你需要從某個地方開始并減少你的列表。一種方法是通過某種指標對域進行排序(我經常使用Majestic 的信任流)。我使用該公式來查找與垃圾郵件域相關的常用詞,例如“submit”、“seo”、“directory”、“free”、“drugs”和“articles”,當然還有更多(“. xyz”是我經常看到的另一個)。該公式會在你的鏈接根域列表中找到任何指定的查詢,讓你可以快速將它們識別為垃圾郵件并將它們添加到你的拒絕列表中。下面的屏幕截圖顯示了一個示例站點的鏈接配置文件,按“Spam”排序,使用上面的過濾器作為標準,然后按信任流的升序排序。本例中使用的公式比我們之前的示例稍長,但遵循相同的模式。
=IF(ISNUMBER(SEARCH("submit",A2)),"Spam",IF(ISNUMBER(SEARCH("seo",A2)),"Spam",
IF(ISNUMBER(SEARCH("directory",A2)),"Spam",IF(ISNUMBER(SEARCH("free",A2)),"Spam",
IF(ISNUMBER(SEARCH("drugs",A2)),"Spam",IF(ISNUMBER(SEARCH("articles",A2)),"Spam",
IF(ISNUMBER(SEARCH(".xyz",A2)),"Spam","Other")))))))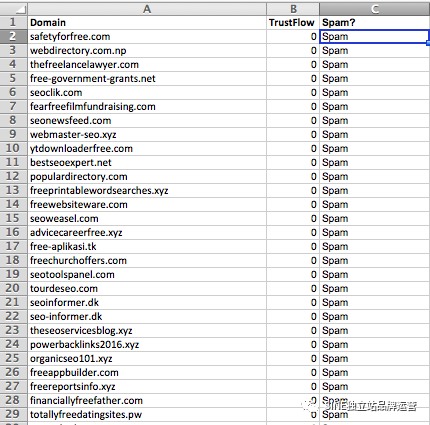
在許多情況下,你的鏈接配置文件會包含來自聽起來合法的域的垃圾鏈接。此公式無法過濾掉所有垃圾郵件,但它通常有助于從你的列表中刪除至少一些域。此外,現在被公式標記為垃圾郵件的某些域可能實際上是合法網站。你應該始終分析此公式的輸出,以確保其正常工作。同樣,它可以作為你拒絕工作的起點,并有望減少某些域,但這絕不是你應該查看的唯一內容。
用例 #3:網站自然流量分析
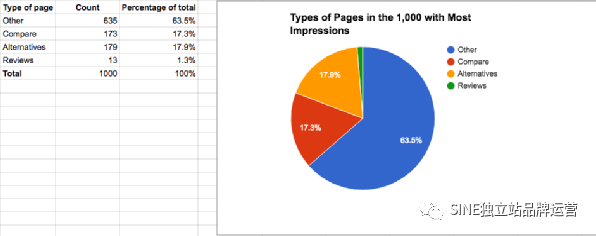
這個分類公式的另一個非常酷的用例是來自 Google Analytics 的數據分析。,我經常分析有關從自然渠道到網站的流量的信息。我將顯示的結果數從 10 更改為 2,500 并導出數據。導出后,我可能想知道哪些類型的頁面往往會獲得最多的流量、最高的轉化率、最多的收入,或者相反。
由于每個站點都不同,你會在每個站點上尋找不同的內容。理想情況下,該站點將具有已建立的子文件夾結構,例如 example.com/blog/article-1、example.com/supplements/product-1 或 example.com/toys/gadget-1。使用 URL 中的這些常見功能,你可以為它們添加任何你喜歡的標簽,可能是“blog”或“supplements”或“toys”,并使用此分類來細分哪些類型的頁面最有效以及在哪里可以改進。
我從 Google Search Console 導出了網站的數據,并按“compare”、“reviews”、“altermatives”和“other”劃分了他們的頁面。由此,我能夠確定我們可以改進的地方,確定有效的方法,并向客戶展示更具體的數據。
公式2
=REGEXEXTRACT(A2,"^(?:https?:\/\/)?(?:[^@\n]?+@?)?(?:www\.)?([^:\/\n]+ )”)
或者
=IFERROR(ARRAYFORMULA(REGEXEXTRACT(A2:A,"^(?:https?:\/\/)?(?:[^@\n]?+@?)?(?:www\.)?([^: \/\n]+)”)),“”)
您可能需要查找某些具有HTTP 與 HTTPS 的博客文章或登錄頁面。
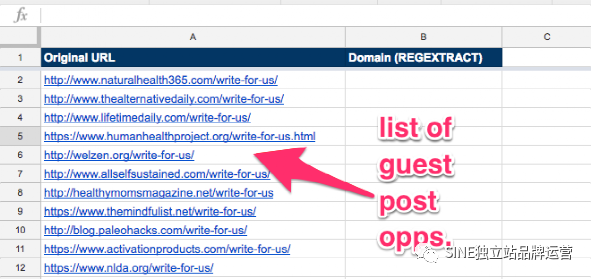
您始終可以使用 Excel 的搜索欄單獨查找它們,但如果您有很長的 URL 列表,這可能會很耗時。相反,使用REGEXTRACT 從您的列表中提取特定數據。
=REGEXEXTRACT(A2,"^(?:https?:\/\/)?(?:[^@\n]?+@?)?(?:www\.)?([^:\/\n]+ )”)
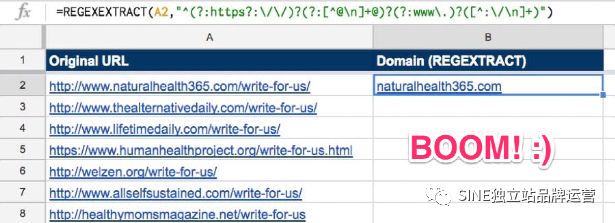
您可以使用 ARRAY 公式一次將其添加到多行。公式看起來很亂,但它有效。
=IFERROR(ARRAYFORMULA(REGEXEXTRACT(A2:A,"^(?:https?:\/\/)?(?:[^@\n]?+@?)?(?:www\.)?([^: \/\n]+)”)),“”)
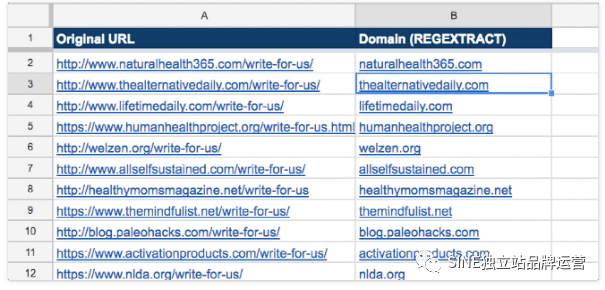
這是使用我們的示例的樣子:

這是最終結果:
概述
Excel基本函數講起來可能需要分很多篇文章,有幸網上有很多帖子都分享到了,大家可以搜索看看。這里我只整理了一些有難度的,我們工作會用到的分享出來,可能也要分幾個篇幅了,今天就先到這里。
分享一個工具SEO in EXCEL(網址:http://seoinexcel.com/)。
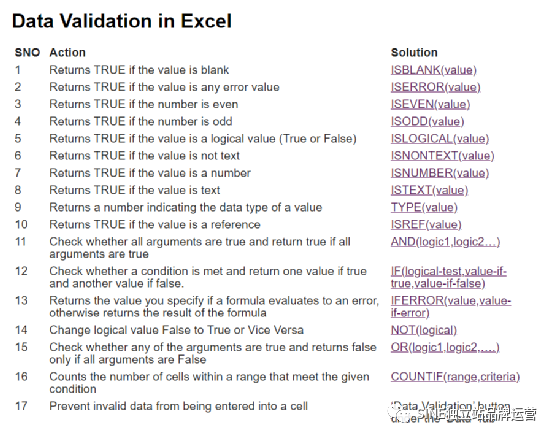
附:SEO要掌握的一些基本的函數截圖


文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)