
當尖叫與奸笑撕破女廁所的平靜 —— 是標識牌誤導讓老實人誤入歧途?還是法外狂徒硬闖?
你的獨立站 robots.txt 正面臨和 【廁所指示牌】同樣困境:爬蟲大軍中混雜著迷路的「誤闖者」也有蓄謀已久的「偷窺狂」。
怎么修改網站的 robots.xtx 文檔
分2部分 Shopify 與 WordPress(Yoast)的路徑指南
1. Shopify 平臺的 robots.txt 修改流程
Shopify 為商家提供了編輯 robots.txt 文件的功能,以此對搜索引擎爬蟲的抓取范圍進行自主調控,具體操作步驟如下:
-
登錄 Shopify 管理后臺
使用商家賬號登錄 Shopify 店鋪的管理頁面。 -
進入主題編輯界面
點擊頁面中的 “在線商店” 選項,隨后選擇 “主題”。在主題頁面中,找到正在使用的 “實時主題” 板塊,點擊其旁邊的 “操作” 按鈕,并選擇 “編輯代碼”。 -
創建 robots.txt 模板
在代碼編輯界面左側的文件目錄中,找到 “模板” 部分,點擊 “添加新模板”。此時會彈出一個選項框,將 “創建新模板用于” 的選項更改為 “robots.txt”,最后點擊 “創建模板”。Shopify 會自動生成一個名為 “robots.txt.liquid” 的文件,這個文件包含了店鋪默認的 robots.txt 規則。 -
編輯 robots.txt 內容
在生成的 “robots.txt.liquid” 文件中,你可以根據實際需求修改規則。比如,若要阻止特定搜索引擎爬蟲訪問某個目錄,可以添加類似 “Disallow: / 特定目錄名 /” 的指令;若要添加網站地圖鏈接,可使用 “Sitemap: https:// 你的域名 /sitemap.xml” 的格式進行添加。完成修改后,點擊保存,新的規則便會生效。
2. 借助 Yoast 插件修改 WordPress 的 robots.txt
Yoast SEO 插件是 WordPress 生態中一款強大的 SEO 優化工具,利用它可以便捷地對 robots.txt 文件進行修改:
-
安裝并激活 Yoast SEO 插件
登錄 WordPress 網站的后臺管理界面,點擊 “插件” 菜單,選擇 “添加新插件”。在搜索框中輸入 “Yoast SEO”,找到該插件后點擊 “安裝” 按鈕,安裝完成后再點擊 “激活”。 -
進入文件編輯器
在 WordPress 后臺左側菜單中點擊 “Yoast SEO”,在展開的選項中選擇 “工具”,然后點擊 “文件編輯器”。若 WordPress 禁用了文件編輯功能,該菜單選項可能不會出現,此時需要先在服務器層面或通過主機提供商開啟文件編輯權限。 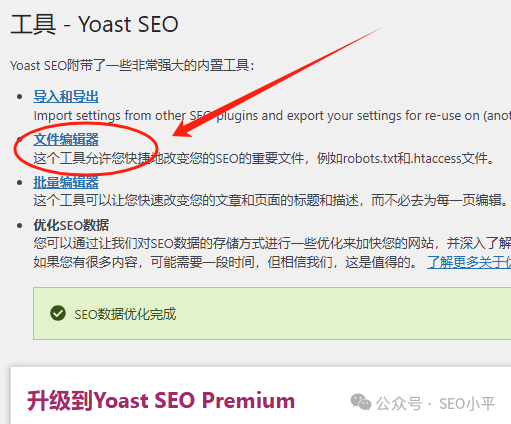
-
編輯 robots.txt
點擊 “創建 robots.txt 文件” 按鈕(若已存在該文件,則直接顯示文件內容),Yoast SEO 會展示生成的默認 robots.txt 內容。在這里,你可以對文件進行編輯操作,例如添加或刪除特定的 “Disallow”“Allow” 指令等。修改完成后,點擊保存即可。
一、基礎規范:從命名到緩存的底層邏輯
1. 命名與位置:爬蟲識別的 “門檻”
-
命名規則
文件名必須嚴格為小寫的 robots.txt,大小寫錯誤(如Robots.TXT)會導致爬蟲直接忽略文件內容,進而引發抓取失控。 -
存儲位置
文件需放置在網站根目錄(如 https://example.com/robots.txt),子目錄存儲(如/pages/robots.txt)無效。此外,不同協議(HTTP/HTTPS)、主機名或子域名(如shop.example.com)需單獨配置獨立的 robots.txt 文件,避免規則沖突。
2. 路徑與指令的大小寫敏感機制
-
路徑匹配
Disallow和Allow指令中的 URL 路徑區分大小寫(如/folder/與/Folder/視為不同規則),錯誤的大小寫會導致規則失效。 -
爬蟲名稱匹配
谷歌對 User-agent值(如Googlebot)不區分大小寫,但其他搜索引擎可能敏感,建議統一使用小寫規范。
3. 緩存機制:修改生效的 “時間差”
-
谷歌通常緩存 robots.txt 內容長達 24 小時,若遇服務器錯誤(如 5xx 狀態碼),緩存時間可能更長。 -
可通過 Cache-Control響應頭的max-age指令調整緩存周期,或借助 Google Search Console(GSC)請求加速刷新。
二、核心指令:精準控制抓取行為的 “工具箱”
1. User-agent:定位目標爬蟲
-
通配符規則
User-agent: *匹配所有遵守協議的爬蟲,規則優先級低于具體爬蟲聲明(如Googlebot)。 -
各種爬蟲細分
針對不同功能的谷歌爬蟲(如 Googlebot-Image負責圖片抓取),可單獨配置規則,實現精細化控制。
2. Disallow 與 Allow:禁止與放行的博弈
-
禁止抓取
Disallow: /可阻止指定爬蟲訪問全站;路徑支持文件(如/private.html)、目錄(如/admin/)或通配符模式(如/*?sessionid=*禁止含會話 ID 的 URL)。 -
精準放行
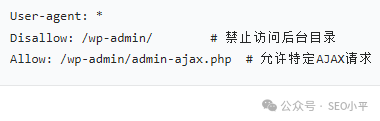
-
路徑長度優先
當同一 URL 匹配多條規則時,路徑前綴最長的規則生效。例如: Allow: /folder/page(長度 12)優于Disallow: /folder/(長度 8)。 -
沖突處理
若路徑長度相同(如 Allow: /page與Disallow: /page),谷歌遵循 “限制性最小” 原則,優先執行Allow。
4. 通配符高級應用:* 與 $ 的組合藝術
-
*?匹配任意字符可用于禁止含特定參數的 URL(如 /*?color=阻止含顏色過濾參數的頁面)或文件類型(如/*.pdf禁止所有 PDF 文件)。 -
$?匹配路徑結尾精準區分目錄與文件(如 Allow: /search/$僅允許根目錄的search頁面,排除/search/results.html)。
三、策略對比:robots.txt 與其他 SEO 工具的協同
robots.txt Disallow |
robots.txt?文件 |
||||
noindex |
<head>?部分 |
||||
X-Robots-Tag: noindex |
|||||
rel="canonical" |
<head>?部分或HTTP響應頭 |
1. 與 noindex 的分工
注意:若頁面在 robots.txt 中被Disallow,谷歌將無法讀取其noindex標簽,導致索引控制失效。
2. 與 Canonical 標簽的互補
-
rel="canonical"用于整合重復內容的權重,需確保非規范頁面可被抓取(即不被 robots.txt 阻止),否則標簽無效。 -
策略選擇
參數化 URL 若需保留鏈接信號,優先使用 canonical;若需徹底阻止抓取,再用Disallow。
四、實戰場景:從參數處理到資源優化
1. 參數化 URL 管理
-
會話 ID 與跟蹤參數
通過 Disallow: /*?sessionid=或/*?utm_source=阻止無價值參數頁面。 -
分面導航
結合通配符(如 /*?*color=)與canonical標簽,保留核心過濾組合頁面,屏蔽冗余參數組合。
2. 分頁內容處理
-
推薦策略
索引第一頁,后續頁面使用 noindex, follow,允許抓取以傳遞鏈接權重。 -
避免誤區
禁止通過 robots.txt阻止分頁 URL,否則會阻斷深層內容的發現路徑。
3. 資源文件抓取策略
-
核心原則
允許抓取 CSS、JS 等渲染必需資源,避免谷歌無法正確解析頁面內容。 -
例外情況
僅當資源為裝飾性或非必要(如第三方跟蹤腳本)時,可謹慎阻止。
在更廣闊的SEO圖景中的定位
robots.txt?禁止抓取某個URL,并不能保證該URL不會被索引如果谷歌通過其他途徑(如外部鏈接、內部鏈接或站點地圖)發現了這個被禁止抓取的URL,它仍然可能將該URL編入索引。正如女廁所有一個側門,有一些男人從側門進入了女廁所。這種情況下,由于谷歌未能抓取頁面內容,搜索結果中通常不會顯示該頁面的描述,有時可能會顯示URL本身或指向該頁面的鏈接錨文本?
我是9年獨立站賣家SEO小平,一直分享谷歌SEO的干貨,更多關于外包SEO的詳細干貨我會在我們的陪跑課程里面系統分享。歡迎報名我們的下次陪跑課程。先加我的微信?Xiao_Ping_Up?,或者掃描二維碼
以往的文章也是干貨,歡迎閱讀和轉發
谷歌算法又雙叒叕更新?Google SEO算法為啥一直在更新?
文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)






