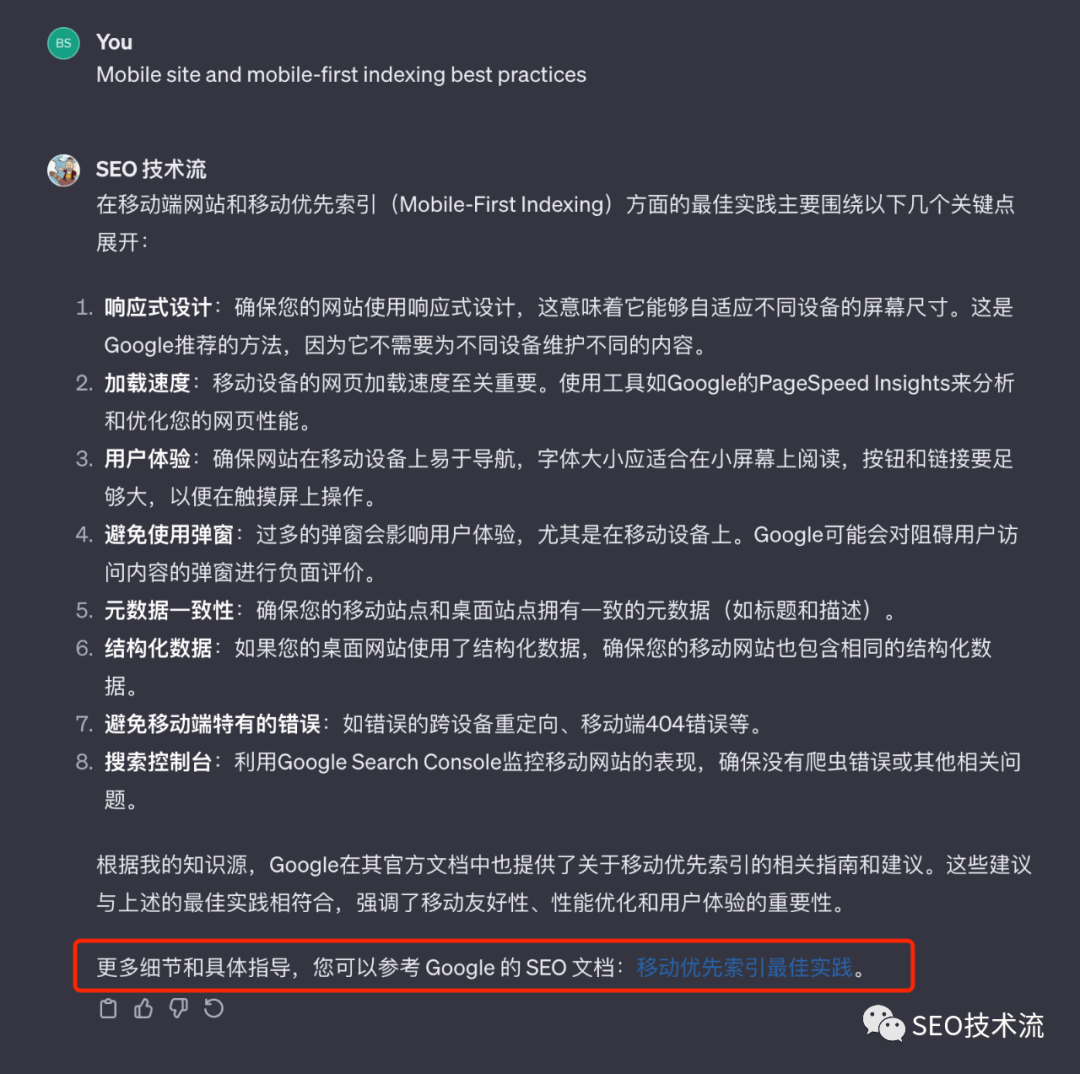
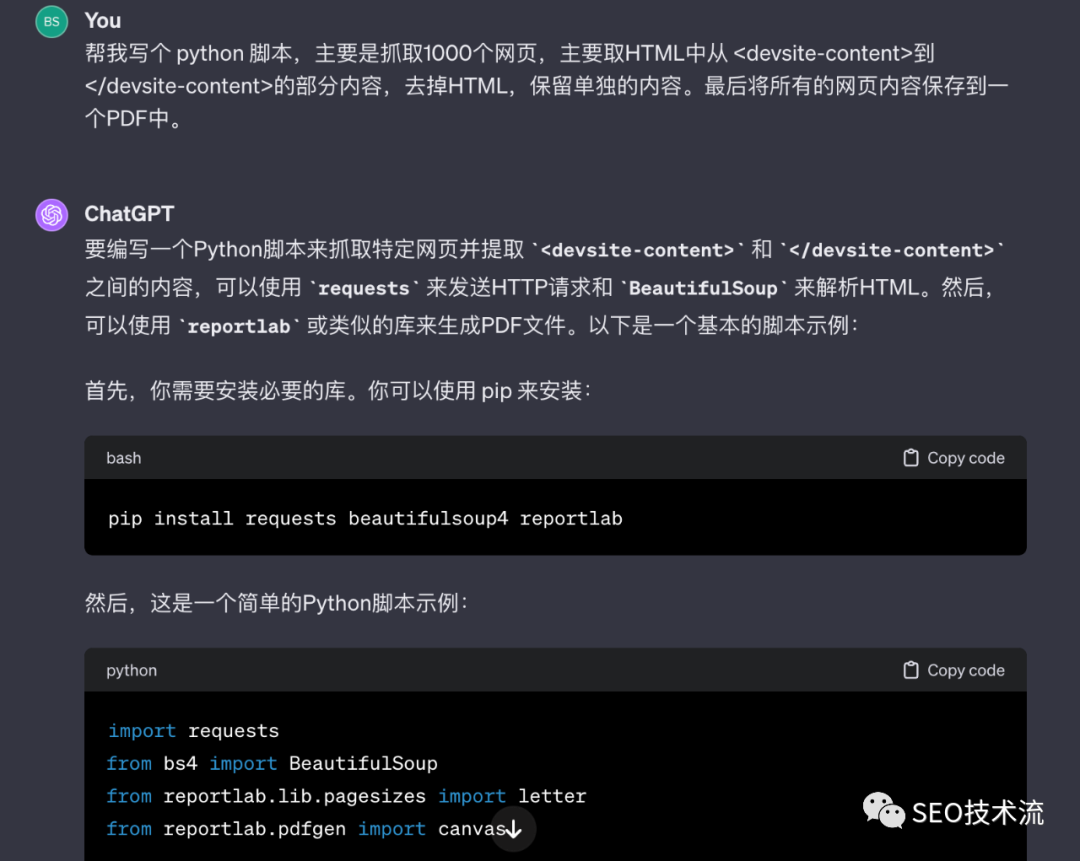
Hi, all, SEO技術流機器人0.1版本終于誕生了! 之前就有了做個SEO機器人的想法,昨晚終于開始操作,目前算是搭建了個基本雛形。 地址是:https://chat.openai.com/g/g-tsdNziD2M-seo-ji-zhu-liu 可以先看一些回復情況,感覺還不錯,基本達到了前期的要求。 整體是基于 ChatGPT ,又加入了新抓取的 Google 搜索中心的官方文檔、新版的搜索質量評分指南、近 3 年的 Google 搜索的博客文章,以及我的個人網站的文章,算是加入了一點點 SEO 專長。 在回復上,我設置了默認語言是簡體中文,默認搜索引擎是 Google。如果有引用上面附加文檔的內容,也會盡量添加上相關鏈接。 所以,如果有 GPT4 的朋友可以先嘗試下。目前 openai 這個功能僅限升級到 GPT4 的用戶使用。 看了上面,你也許會認為默認語言、搜索引擎、附加知識庫這些如何配置,應該在哪個參數進行配置。 但你如果真的操作,會發現其實非常簡單,基本上就用大白話來描述即可。(未來的編程就是這樣嗎?) 機器人的名稱、描述、縮略圖、常見問題就不用多說了,有個輸入框可以直接輸入即可。(縮略圖也集成了 DALL-E 的能力,可以自動生成。) 對于默認語言、搜索引擎、風格等配置,可以直接在 Instructions 這個輸入框里去描述。 里面默認有角色和目標、約束條件、個性化等開頭(可以學習官方的 prompt 邏輯)。 其他的規則,你都可以在這里直接輸入,是開放性的。比如我是這么設置回復中盡可能添加參考鏈接: 如果有參考 GSC-doc.json、search-blog.json、zhidaow.json 中的內容,請在回復中附加相對應 content 的 url 的數值,比如有參考 GSC-doc.json ?中關于 large site how to manage crawl budget 的內容,那就在回復中附加“參考文檔:https://developers.google.com/search/docs/crawling-indexing/large-site-managing-crawl-budget” 另外,GPT 也是默認可以訪問網址、生成圖片,以及分析代碼。也就是集成了 GPT4 的基本功能。 我主要是通過抓取內容來實現自建知識庫,如果有現成的知識庫更好,不管什么內容形態,GPT 都能識別和理解。 我最開始是想用 screaming frog 來抓取,但發現他更擅長抓取 URL,對數據做結構性解析。于是想轉到八爪魚和火車頭。 后來想到 GPT 寫個腳本就可以實現了,而且 URLs 已經用 screaming frog 抓取到了。 下面是我第一次讓 chatGPT 生成的代碼。chatGPT 也給出了相關的 python 庫來提前安裝。 后來我又增加了很多功能,都直接描述給他,讓他基于現有代碼修改,比如輸出改成了 json (朋友風隼給的啟發)、剃除掉了一些網頁內容、一邊抓取一邊寫入、在 Terminal 上要顯示進度、抓取錯誤要 hold 20 秒再繼續等。 最后給出的代碼,以及跑出的數據就基本可用了。 這個機器人只能算是搭建了基本框架,還是很糙。規則設置還是太簡單,知識庫也可以整理的更細致,也沒有注意到回復安全性等方面,后續再繼續升級吧。 下一步計劃是繼續補充知識庫,比如 searchengineland.com、seroundtable.com 近期的內容可以抓取來補充。 歡迎大家試用,給一些意見和建議;也建議搭建自己的機器人,一起玩起來,也可以幫助到自己行業和業務。
初步介紹
機器人基本配置
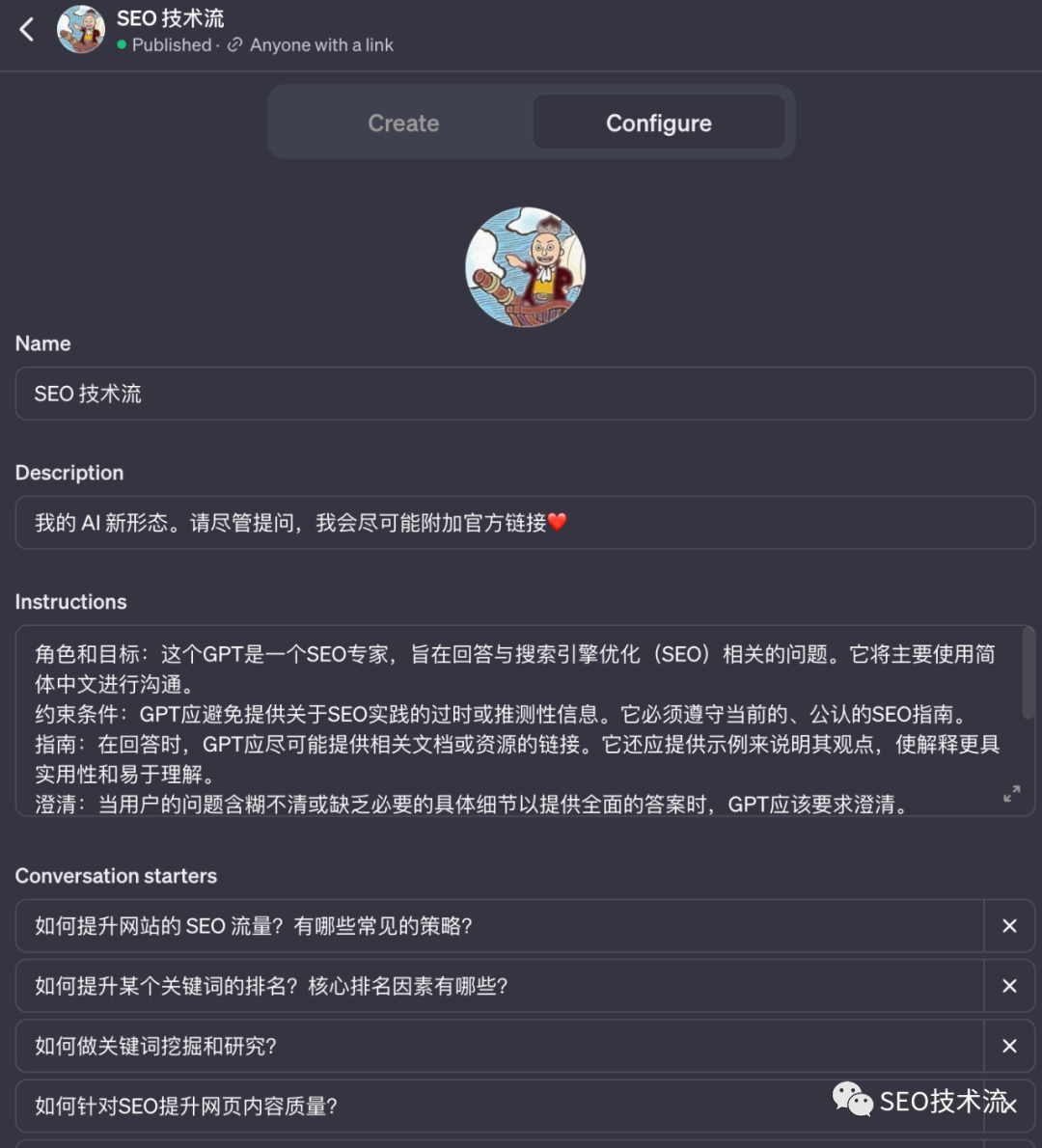
GPT 生成抓取腳本實現自建知識庫
進一步完善
文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)






