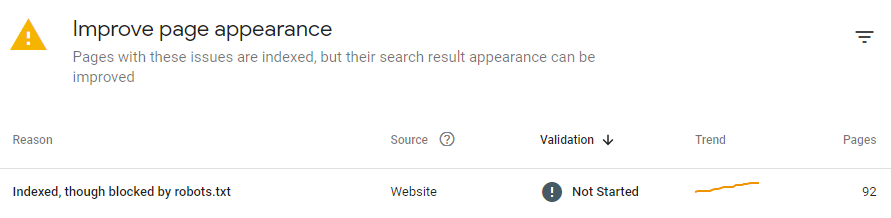
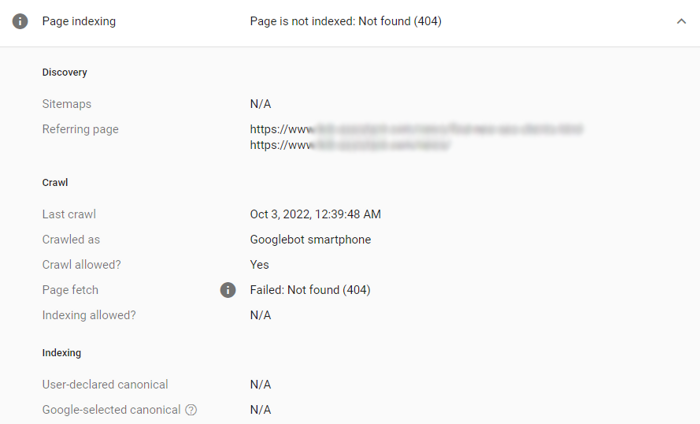
收錄對于GoogleSEO至關(guān)重要。 如果谷歌沒有收錄你的網(wǎng)頁,你所做的一切SEO工作都會變得毫無價值,哪怕你已經(jīng)針對一個頁面進(jìn)行了臻于完美的優(yōu)化,并能確保它將帶來絕佳的用戶體驗(yàn)。殘酷的現(xiàn)實(shí)是:未被收錄的頁面不會進(jìn)入搜索結(jié)果頁(SERP),也不會帶來任何流量和轉(zhuǎn)化。 同樣,如果谷歌偶然收錄了一個本不應(yīng)該被收錄的頁面,那么你就有可能面臨私人信息泄露、收到谷歌對低質(zhì)量內(nèi)容的懲罰等其他嚴(yán)重的后果。 ▊?在本指南中,我們將探索Google收錄的常見問題,以及如何解決它們。但首先,讓我們來看看如何檢查你的網(wǎng)站是否存在收錄問題。 01 如何發(fā)現(xiàn)收錄問題? Google SearchConsole可以幫助你發(fā)現(xiàn)你的網(wǎng)站存在哪些收錄問題,請點(diǎn)擊收“收錄”(Index)>“頁面”(Page)以查看,如下圖所示。 只要是未被Google收錄的頁面,不管是因?yàn)槭裁丛颍紩y(tǒng)一顯示在“未收錄”(NotIndexed)部分。被Google收錄,但是存在其他問題等待你解決的頁面將會顯示在底部的“改善頁面外觀”(Improvepage appearance)部分。 Google SearchConsole將提供更多細(xì)節(jié),幫助你確定頁面的問題所在,如下圖: 在了解如何發(fā)現(xiàn)網(wǎng)站存在的收錄問題后,我們可以探討解決方案啦。當(dāng)然,本文探討的所有解決方案,都是針對需要收錄的網(wǎng)頁。如果你的頁面不需要被Google收錄,你可以采用noindex標(biāo)簽,或者通過robots.txt指令的限制Google訪問相關(guān)頁面。此外,確保將這些網(wǎng)頁從你的網(wǎng)站地圖(sitemap)中刪除。當(dāng)然,如果這些頁面本就未被收錄,那么你無需采取任何行動。 02 如何解決Google收錄問題? 1??404錯誤:網(wǎng)頁未找到(Not found 404) 404網(wǎng)頁未找到(Notfound404),或者失效URL,應(yīng)該是最常見的收錄問題之一。很多原因都可能導(dǎo)致HTTP狀態(tài)碼出現(xiàn)404,比如,你已經(jīng)刪除了URL,但沒有從網(wǎng)站地圖(sitemap)中或站內(nèi)其它頁面中刪除該失效URL,URL有誤,等等。 Google曾提示404本身并不損害網(wǎng)站性能,除非這些URL是主動提交給Google收錄的URL。那么,如果你在收錄報(bào)告中看到404網(wǎng)址,應(yīng)該如何修復(fù)呢?我們提供以下解決方案: ● 更新你的網(wǎng)站地圖(sitemap),檢查受影響的URL是否有誤。 ● 如果該頁面已經(jīng)遷移到一個新的地址,設(shè)置一個301重定向。 ● 如果該頁面已經(jīng)被刪除,也沒有任何替換網(wǎng)頁,那么將其保留為404,但從網(wǎng)站地圖(sitemap)中刪除,假如站內(nèi)其它頁面有鏈接到該頁面,該內(nèi)鏈也需要同步刪除或更新。這樣,Google就不會再試圖找到并抓取這個頁面了。 ● 如果你需要保留404,那就創(chuàng)建一個用戶友好型404頁面--你可以在那里添加一些有用的鏈接,使用戶繼續(xù)停留在你的網(wǎng)站上,而不是直接關(guān)閉頁面。但有一點(diǎn)需要記住,404頁面的性質(zhì)并不會因此改變,你依舊應(yīng)該禁止Google收錄它。 ● 請注意,Google Search Console現(xiàn)在并不區(qū)分404(Not found,未找到)和410(gone,已消失),而是將它們都分類進(jìn)404報(bào)告中。這兩個代碼曾經(jīng)是不同類型的響應(yīng)代碼。404意味著 "沒有找到,但以后也許可以找到",而410代表 "現(xiàn)在沒有找到,未來也不會找到,因?yàn)樗呀?jīng)永遠(yuǎn)消失了"。現(xiàn)在,Google對404和410頁面采取的措施是一樣的。 所以,如果你在404報(bào)告中發(fā)現(xiàn)一個410的頁面,不要感到奇怪。我們建議你不要保留空的410頁面,而是設(shè)置一個自定義的404頁面,降低用戶跳出率。許多SEO從業(yè)者和站長有一個習(xí)慣,就是把404重定向到網(wǎng)站主頁,但事實(shí)上,這并不是最好的做法。它會讓Google覺得混亂,并導(dǎo)致“軟404”(Soft 404)。 2??軟404錯誤(Soft 404) 當(dāng)一個網(wǎng)頁,HTTP狀態(tài)碼出現(xiàn)200(服務(wù)器成功返回網(wǎng)頁),但Google無法找到它的內(nèi)容并認(rèn)為它是一個404錯誤的時候,就會出現(xiàn)軟404(Soft404)問題。軟404的出現(xiàn)通常是由以下原因造成的: ① 服務(wù)器端文件丟失 ② 與數(shù)據(jù)庫的連接中斷 ③ 網(wǎng)站的內(nèi)部搜索頁結(jié)果為空 ④ 未加載或丟失JavaScript文件 ⑤ 頁面內(nèi)容太少 ⑥ 頁面隱蔽 這些問題實(shí)際上并不難解決,下面是一些常見的解決方案: ● 如果網(wǎng)頁內(nèi)容已經(jīng)遷移,該頁面內(nèi)容為空,且HTTP狀態(tài)碼顯示200 OK,那么設(shè)置一個301重定向到新的地址。 ● 如果被刪除的內(nèi)容頁沒有替代頁,請將其標(biāo)記為404并從網(wǎng)站地圖(sitemap)中刪除。 ● 如果該頁面應(yīng)該存在,請豐富該頁面內(nèi)容,并檢查該頁面上的所有腳本是否被正確渲染和顯示(例如被robots.txt禁止,瀏覽器不支持,等等)。 ● 如果錯誤發(fā)生的原因是Google bot試圖獲取該頁面時,服務(wù)器出現(xiàn)故障,請檢查服務(wù)器是否正常工作,然后要求Google重新收錄該網(wǎng)頁。 3??401錯誤:網(wǎng)頁未授權(quán) HTTP401錯誤代表Googlebot沒有網(wǎng)頁訪問權(quán)限,需要進(jìn)行身份認(rèn)證。如果你希望該頁面被收錄,請授予Googlebot相關(guān)的權(quán)限,或者刪除網(wǎng)頁的授權(quán)要求。 4??403錯誤:訪問被禁止 這種類型的錯誤發(fā)生在用戶代理提供了進(jìn)入該頁面的憑證(登錄、密碼),但“執(zhí)行”訪問被禁止。所以服務(wù)器返回403,而不是預(yù)期的頁面。 如果一個頁面被錯誤地禁止訪問了,而你又確實(shí)需要Google收錄它,那么你應(yīng)該允許未登錄的用戶訪問該頁面,或者允許Googlebot進(jìn)入該頁面,以閱讀和收錄它。 5??網(wǎng)址已提交,但帶有“noindex”標(biāo)記 當(dāng)你明確要求谷歌收錄一個頁面(即把它添加到網(wǎng)站地圖或手動請求Google收錄),但該頁面有一個noindex標(biāo)簽時,這個錯誤就會發(fā)生。解決方案很簡單--刪除noindex標(biāo)簽,谷歌就可以訪問并收錄該頁面。 6??robots.txt設(shè)置了不可被抓取 如果你通過robots.txt屏蔽了某個頁面,那么谷歌將不會抓取收錄它。只要移除這些限制,Google就會收錄這個頁面。 ?注意:Robots.txt并不能確保一個網(wǎng)頁不被收錄。有時,GoogleSearch Console可能會顯示:“已收錄,盡管遭遇robots.txt阻止(Indexed,though blockedby robots.txt)” 這種情況比未被Google收錄要麻煩得多。因?yàn)镚oogle可能會訪問一些私密信息(比如購物車、私人數(shù)據(jù)等),并將其展示在搜索結(jié)果頁。 如果遇見這種情況,請先確認(rèn)是否需要Google收錄該頁面。如果是,從robots.txt文件中刪除該網(wǎng)頁URL。如果不是,也需要把這個URL從robots.txt中刪除,但同時應(yīng)用noindex標(biāo)簽,或限制非授權(quán)用戶的訪問。在采取限制措施后,你也可以通過GoogleSearch Console選擇“收錄(index)”>“移除(Removals)”>“新請求(Newrequest)”要求谷歌從收錄中移除該網(wǎng)頁。 以上六個常見問題的解決方案學(xué)會了嗎?在下一篇文章中,我們將繼續(xù)聚焦Google收錄的疑難雜癥!快點(diǎn)關(guān)注和收藏,才不會錯過《Google收錄的常見問題及解決方案指南(下)》更新!



黑色音符")


文章為作者獨(dú)立觀點(diǎn),不代表DLZ123立場。如有侵權(quán),請聯(lián)系我們。( 版權(quán)為作者所有,如需轉(zhuǎn)載,請聯(lián)系作者 )

網(wǎng)站運(yùn)營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨(dú)立站交流群。
群里有不少運(yùn)營大神,不時會分享一些運(yùn)營技巧,更有一些資源收藏愛好者不時分享一些優(yōu)質(zhì)的學(xué)習(xí)資料。
現(xiàn)在可以掃碼進(jìn)群,備注【加群】。 ( 群完全免費(fèi),不廣告不賣課!)