在內容營銷的過程中,數據的作用毋庸置疑。記得我剛開始工作的時候,要批量去抓取網站的數據,基本都需要通過寫代碼的方式。想省時省力得抓到自己想要的數據,并不是一件容易事。
后面慢慢出現了像火車頭、八爪魚這樣的 No Code 工具,才使得數據的抓取變得容易了一些。但要想抓到非常自定義的數據,也并不是那么方便(還是得寫代碼)。
由于最近我一直在做 Programmatic SEO,需要采集不同網站上的不同數據,所以就花了點心思在調研各種數據抓取方案的比較上。
偶然間發現了一種最近比較流行的開源爬蟲(FireCrawl),自認為還是挺有研究價值的,專門用一篇文章記錄下。
首先,使用這款工具可以很輕松將網頁的信息整理下來,即將 URL 鏈接上的信息轉化為 Markdown 格式的數據。并且這些數據可以很輕松的投喂給大模型,以便對數據后續的進一步加工。
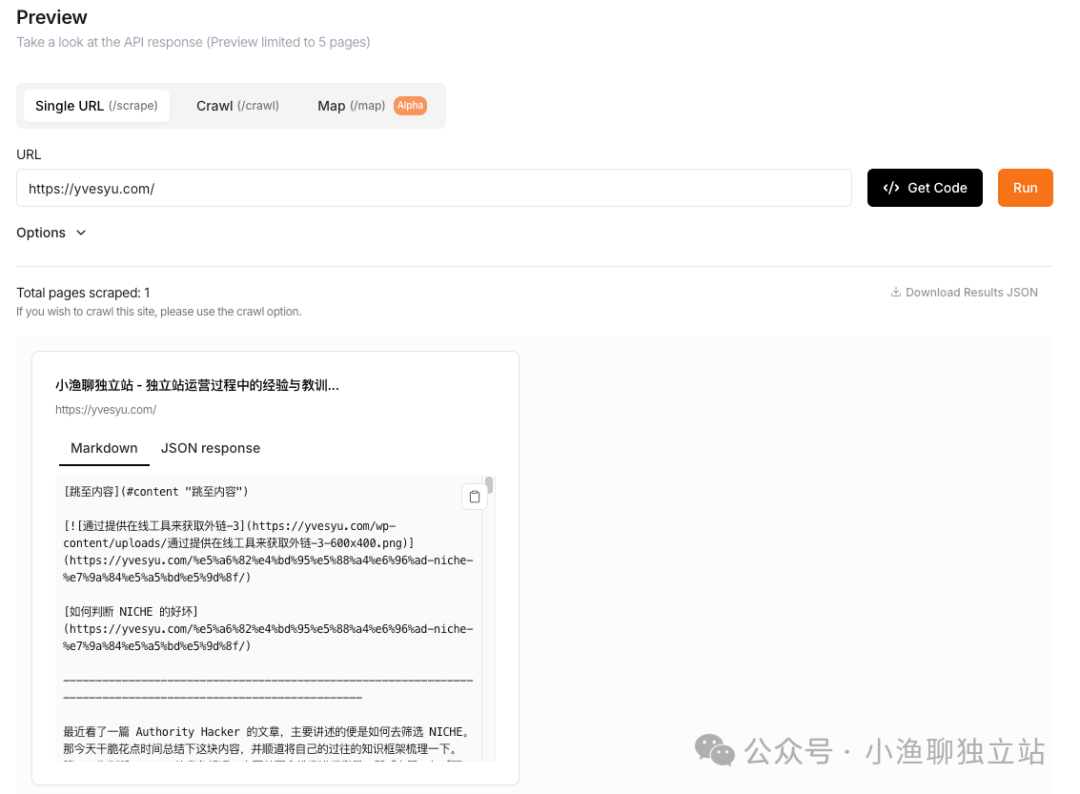
比如我現在想抓取我博客的內容,只需要簡單將鏈接扔到輸入框里點擊確定,稍等片刻便可以看到所有的數據都已經使用 Markdown 格式整理好了。
并且,這款爬蟲還支持各種各樣的 SDK,支持自定義部署。同時也提供 LLM 大模型的接入,也就是直接利用大模型的分析能力,將網頁上的數據格式化整理后呈現出來,且整個過程根本不需要我們寫什么代碼。
至于具體的自定義部署,我現在還沒來得及研究。但我腦子里能清楚知道,這玩意兒結合 Programmatic SEO,真的有挺多有意思的玩法。這里先賣個關子吧,等我哪天做成了再來分享。
所以現階段的主要任務就是熟悉這套程序,搞明白如何高效率使用。可能得話再將這套流程納入到自己的工作流中去,進一步提升工作效率。
大家有興趣的可以去試試。

文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)






