要做好網(wǎng)站SEO,首先要做的是思維上的轉(zhuǎn)變,理解和接受這些最新的SEO做法。了解在這個充滿不確定的環(huán)境下,網(wǎng)站如何符合Google排名規(guī)律,才有可能在外貿(mào)數(shù)字營銷時代大展身手。
今天就來說說Google SEO的一些基本知識。

什么是谷歌SEO

我們常說的Google SEO,其實是Google搜索引擎優(yōu)化(Search Engine Optimization,簡稱SEO)。
可以這樣拆分理解:Google + 搜索引擎 + 優(yōu)化。
Google:?這里的搜索引擎特指是Google,Google全世界用的最多,大概占了92%。當然還有其他搜索引擎,比如360,Bing,百度,Yahoo!等等,給大家看看數(shù)據(jù):
?? ? ??? ? ? ?
搜索引擎:?這些搜索引擎的核心模塊一般包括爬蟲、索引、檢索和排序等,這些模塊有各種規(guī)則,但目的只有一個:為信息檢索用戶提供快速、高相關(guān)性的信息查詢服務。
優(yōu)化:?有大量的查詢結(jié)果,就會有排名前后之分,于是就有搜索排名。優(yōu)化排名也就是通過一系列網(wǎng)站規(guī)劃,讓網(wǎng)站排名更高。
說到這里,你應該能get到Google搜索引擎優(yōu)化了吧?
一句話概括:根據(jù)Google的搜索引擎排名規(guī)則,來規(guī)劃整站,確保網(wǎng)站從內(nèi)容、結(jié)構(gòu)、鏈接等盡量符合Google排名規(guī)律,能在Google搜索結(jié)果中獲得較好的排位。
而高排位的背后,往往意味著詢盤。
谷歌搜索的基本原理
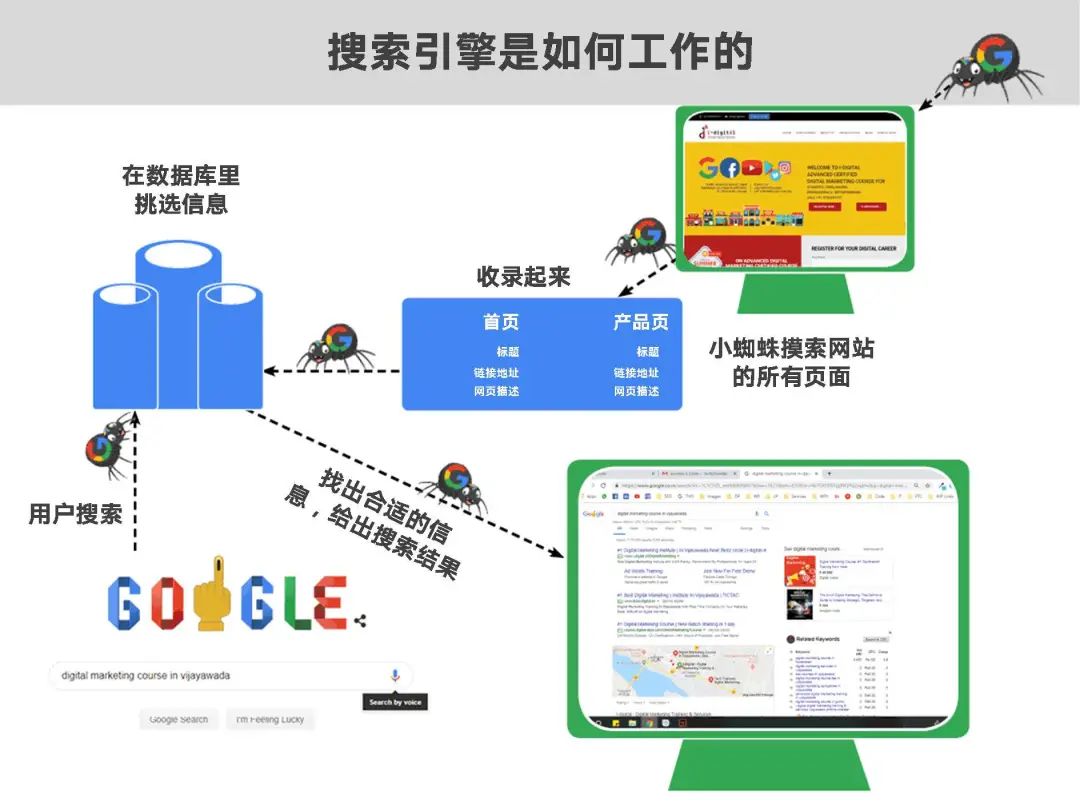
原理理解起來很簡單,最重要有三步:抓取,收錄,排名。
抓取:就是Google蜘蛛爬取網(wǎng)站的這個過程。Google的官方解釋是——“抓取”是指找出新網(wǎng)頁或更新后的網(wǎng)頁以將其添加到 Google 中的過程。
-
收錄:就是搜索引擎把頁面存儲到其數(shù)據(jù)庫的結(jié)果,也叫索引。Google的官方解釋是:蜘蛛已訪問該網(wǎng)頁、已分析其內(nèi)容和含義并已將其存儲在 Google 索引中。已編入索引的網(wǎng)頁可以顯示在 Google 搜索結(jié)果中。
排名:在上一步爬蟲收錄了你的內(nèi)容到Google自己的搜索引擎數(shù)據(jù)庫,收錄了不代表立馬有排名,Google對于新網(wǎng)站有個考察期,考察期內(nèi)網(wǎng)站內(nèi)容更新節(jié)奏比較穩(wěn)定,沒有惡意垃圾外鏈操作,Google開始慢慢放開給你排名。
來個形象生動的圖片說明:
 ??
??
Google的這個排名也是根據(jù)用戶在你網(wǎng)站上面的表現(xiàn),例如網(wǎng)站停留時間,跳出率,退出率。
這個指標站長也可以通過安裝Google的Analytics分析代碼到自己的網(wǎng)站,然后進入GA后臺看到網(wǎng)站的數(shù)據(jù)表現(xiàn)。
說到這里,很多外貿(mào)朋友在建好網(wǎng)站之后會有疑問,我的網(wǎng)站到底被收錄了沒?
-
通過Site命令。主流的搜索引擎如Google,Baidu及Bing都是支持Site命令的。通過Site命令可以在宏觀層面查看一個網(wǎng)站被收錄了多少頁面,這個數(shù)值是不精確的,有一定的波動性,但是具有一定的參考價值。
如果網(wǎng)站已經(jīng)驗證Google Search Console,這就可以獲取網(wǎng)站被Google收錄的精確數(shù)值。
發(fā)現(xiàn)自己網(wǎng)站有一些重要頁面沒有被收錄怎么辦?別慌,有幾個常見的原因,可以自己檢查,或者讓你的技術(shù)人員排查一下。
使用了Meta標簽“Noindex”
如果頁面的Meta標簽中添加了<META NAME=”ROBOTS”CONTENT=”NOINDEX, NOFOLLOW”>的代碼,就是在告訴搜索引擎不要索引該頁面,那就不會被收錄了。
在Robots文件中使用了Disallow
如果在網(wǎng)站的Robots文件中添加了User-agent: * Disallow: /ABC/ 的代碼,則是告訴搜索引擎不要索引ABC目錄下的所有頁面。Robots文件中的命令優(yōu)先級是比頁面Meta標簽的命令高的,Google會嚴格遵循Robots文件中的命令,但是頁面Meta中的命令有時候會被忽略。如一個頁面即使在Meta代碼中明確加了Index的指令,但是在Robots文件中是Disallow的話,搜索引擎也不會收錄該頁面。
網(wǎng)站缺少Sitemap文件
Sitemap文件是搜索引擎抓取網(wǎng)站頁面的有效途徑之一,如果網(wǎng)站缺少sitemap文件,或者sitemap中不包含頁面URL,這都有可能造成網(wǎng)站或頁面不被收錄。
錯誤使用Canonical標簽
Canonical標簽主要用于兩個頁面間內(nèi)容一樣,但是URL不一樣的情況,如很多有SEM投放需求的站長,為了跟蹤廣告效果,需要給Landing Page添加多個UTM跟蹤參數(shù);Canonical標簽就能規(guī)范化這一批URL,讓搜索引擎理解這些不同URL間的關(guān)系,避免內(nèi)容的重復和權(quán)重的分散。但是如果A和B兩個頁面間的內(nèi)容不一樣,卻給A頁面加上了指向B頁面的Canonical標簽,這就會導致搜索引擎不能很好理解頁面間的關(guān)系,因而不收錄目標頁面。
除了這些原因,還有可能是因為:
錯誤使用301及302重定向?
網(wǎng)站或頁面很新
URL過于復雜或錯誤
頁面層級過深
頁面內(nèi)容重復
-
網(wǎng)站被懲罰
原因很多,最好找專業(yè)人士給你排查一遍。
谷歌 SEO 優(yōu)化:站內(nèi)優(yōu)化+關(guān)鍵詞策劃及部署+原創(chuàng)內(nèi)容+視頻+外鏈,
全面提升網(wǎng)站權(quán)重與排名;純?nèi)斯げ僮鳎瑹o風險,適合長期主義的推廣方案;
谷歌SEM代投:Google精準搜索關(guān)鍵詞廣告,助您低成本&快速開始推廣。低門檻快速啟動、專業(yè)團隊運營。
低成本谷歌SEO優(yōu)化+SEM代投,詳情可加VX了解:18565532501
文章為作者獨立觀點,不代表DLZ123立場。如有侵權(quán),請聯(lián)系我們。( 版權(quán)為作者所有,如需轉(zhuǎn)載,請聯(lián)系作者 )

網(wǎng)站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優(yōu)質(zhì)的學習資料。
現(xiàn)在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)