谷歌研究論文(文章底部有論文原文鏈接)描述了一個叫 TW-BERT 的出色框架,無需重大更改即可提高搜索排名。
? ? ? ? ?
§TW-BERT 是一個端到端查詢詞權重框架,它連接兩種范式改善搜索結果
§與現有查詢擴展模型集成,并提高性能
§部署該框架需要更少更改
? ? ? ? ?
谷歌宣布了一個名為Term Weighting BERT(TW-BERT) 的優秀的排名框架,它可以改善搜索結果,并且易于在現有排名系統中進行部署。
? ? ? ? ?
盡管谷歌尚未確認它正在使用 TW-BERT,但這個新框架是一個突破,它全面改進了排名流程,包括查詢擴展。它也很容易部署,在我看來,這使得它更有可能被使用。
? ? ? ? ?
TW-BERT 有許多共同作者,其中包括Google DeepMind 杰出研究科學家、Google Research 前研究工程高級總監Marc Najork 。Marc Najork與人合著了許多與排名過程相關的主題和許多其他領域的研究論文。
? ? ? ? ?
Marc Najork 被列為合著者的論文包括:
?關于優化神經排序模型的 Top-K 指標 – 2022
?用于不斷發展的內容的動態語言模型 – 2021
?重新思考搜索:讓業余愛好者成為領域專家 – 2021
?神經排序模型的特征轉換 – – 2020
?在 TF-Ranking 中使用 BERT 學習排名 – 2020
?長篇文檔的語義文本匹配 – 2019
?TF-Ranking:用于學習排序的可擴展 TensorFlow 庫 – 2018
?用于排名指標優化的 LambdaLoss 框架 – 2018
?學習在個人搜索中利用選擇偏差進行排名 - 2016
什么是 TW-BERT? ?
TW-BERT 是一個排名框架,它為搜索查詢中的單詞分配分數(稱為權重),以便更準確地確定哪些文檔與該搜索查詢相關。TW-BERT 在查詢擴展中也很有用。
? ? ? ? ?
查詢擴展是一個重述搜索查詢或向其添加更多單詞(例如將單詞“recipe”添加到查詢“chicken soup”)以更好地將搜索查詢與文檔匹配的過程。向查詢添加分數有助于更好地確定查詢的內容。
TW-BERT 連接兩種信息檢索范式 ?
該研究論文討論了兩種不同的搜索方法。一種是基于統計的,另一種是深度學習模型。
接下來討論了這些不同方法的優點和缺點,并提出 TW-BERT 是一種彌合這兩種方法且沒有任何缺點的方法。
? ? ? ? ?
論文提到:
? ? ? ? ?
“These statistics based retrieval methods provide efficient search that scales up with the corpus size and generalizes to new domains.
“這些基于統計的檢索方法提供了有效的搜索,可以隨著語料庫的大小進行擴展并推廣到新的領域。
? ? ? ? ?
However, the terms are weighted independently and don’t consider the context of the entire query.”
然而,這些術語是獨立加權的,并且不考慮整個查詢的上下文。”
? ? ? ? ?
研究人員隨后指出,深度學習模型可以找出搜索查詢的上下文。
? ? ? ? ?
解釋如下:
? ? ? ? ?
“For this problem, deep learning models can perform this contextualization over the query to provide better representations for individual terms.”
“對于這個問題,深度學習模型可以對查詢執行上下文化,以便為各個術語提供更好的表示。”
? ? ? ? ?
研究人員建議使用 TW-Bert 來連接這兩種方法。
? ? ? ? ?
該突破性描述是這樣的:
? ? ? ? ?
“We bridge these two paradigms to determine which are the most relevant or non-relevant search terms in the query…
“我們將這兩種范式聯系起來,以確定查詢中哪些是最相關或不相關的搜索詞......
? ? ? ? ?
Then these terms can be up-weighted or down-weighted to allow our retrieval system to produce more relevant results.”
然后可以提高或降低這些術語的權重,以使我們的檢索系統能夠產生更相關的結果。”
TW-BERT 搜索詞權重示例 ?
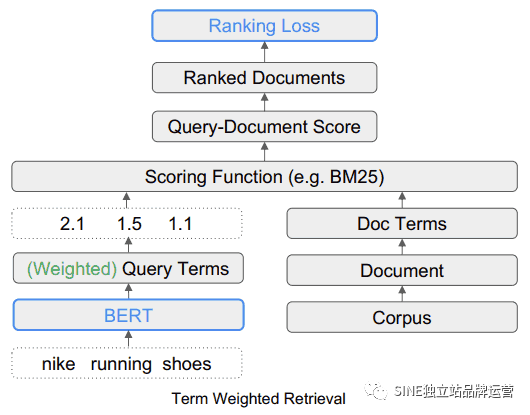
該研究論文提供了搜索查詢“Nike running Shoes”的示例。簡單來說,“Nike running Shoes”這個詞是排名算法必須按照搜索者想要理解的方式來理解的三個詞。他們解釋說,強調查詢的“running”部分會顯示包含耐克以外品牌的不相關搜索結果。在該示例中,品牌名稱 Nike 很重要,因此排名過程應要求候選網頁中包含“Nike”一詞。
? ? ? ? ?
候選網頁是正在考慮用于搜索結果的頁面。TW-BERT 的作用是為搜索查詢的每個部分提供一個分數(稱為權重),以便它以與輸入搜索查詢的人有相同意義的方式。在這個例子中,Nike這個詞被認為很重要,所以應該給它一個更高的分數(權重)。? ? ??
論文提到:
? ? ? ? ?
“Therefore the challenge is that we must ensure that Nike” is weighted high enough while still providing running shoes in the final returned results.”
“因此,挑戰在于我們必須確保“Nike”的權重足夠高,同時在最終返回的結果中仍然提供running shoes。”
? ? ? ? ?
另一個挑戰是理解“running”和“shoes”這兩個詞的上下文,這意味著將這兩個詞連接為短語“running shoes”時,權重應該更高,而不是分別設置這兩個詞的權重。
? ? ? ? ?
解釋如下:
“The second aspect is how to leverage more meaningful n-gram terms during scoring.
“第二個方面是如何在評分過程中利用更有意義的 n-gram語法術語。
? ? ? ? ?
In our query, the terms “running” and “shoes” are handled independently, which can equally match “running socks” or “skate shoes”.
在我們的查詢中,術語“running”和“shoes”是獨立處理的,它們同樣可以匹配“running socks”或“skate shoes”。
? ? ? ? ?
In this case, we want our retriever to work on an n-gram term level to indicate that “running shoes” should be up-weighted when scoring.”
在這種情況下,我們希望我們的檢索器在 n-gram 術語級別上工作,以表明“running shoes”在評分時應該增加權重。”
解決當前框架的局限性 ?
該研究論文總結了傳統的加權在查詢變化方面的局限性,并提到那些基于統計的加權方法在零樣本場景中表現不佳。零樣本學習是指模型解決未經訓練的問題的能力。
還總結了當前術語擴展方法固有的局限性。術語擴展是指使用同義詞來查找搜索查詢的更多答案或推斷另一個單詞時。例如,當有人搜索“chicken soup”時,它會被推斷為“chicken soup recipe”。
? ? ? ? ?
論文當前方法的缺點:
? ? ? ? ?
“…these auxiliary scoring functions do not account for additional weighting steps carried out by scoring functions used in existing retrievers, such as query statistics, document statistics, and hyperparameter values.
“......這些輔助評分函數不考慮現有檢索器中使用的評分函數執行的額外加權步驟,例如查詢統計、文檔統計和超參數值。
? ? ? ? ?
This can alter the original distribution of assigned term weights during final scoring and retrieval.”
這可能會改變最終評分和檢索期間分配的術語權重的原始分布。”
? ? ? ? ?
接下來,研究人員表示,深度學習有其自身的復雜性,即部署它們的復雜性以及當它們遇到未經過預先訓練的新領域時的不可預測的行為。這就是 TW-BERT 發揮作用的地方。
TW-BERT 連接兩種方法 ?
它所提出的解決方案類似于混合方法。在下面的引用中,術語 IR 表示信息檢索。
? ? ? ? ?
論文提到:
“To bridge the gap, we leverage the robustness of existing lexical retrievers with the contextual text representations provided by deep models.
“為了彌補這一差距,我們利用現有詞匯檢索器的穩健性和深度模型提供的上下文文本表示。
? ? ? ? ?
Lexical retrievers already provide the capability to assign weights to query n-gram terms when performing retrieval.
詞匯檢索器已經提供了在執行檢索時為查詢n-gram語法術語分配權重的功能。
? ? ? ? ?
We leverage a language model at this stage of the pipeline to provide appropriate weights to the query n-gram terms.
我們在這個階段利用語言模型為查詢n-gram詞項提供適當的權重。
? ? ? ? ?
This Term Weighting BERT (TW-BERT) is optimized end-to-end using the same scoring functions used within the retrieval pipeline to ensure consistency between training and retrieval.
該術語加權 BERT (TW-BERT) 使用檢索使用的相同評分函數進行端到端優化,以確保訓練和檢索之間的一致性。
? ? ? ? ?
This leads to retrieval improvements when using the TW-BERT produced term weights while keeping the IR infrastructure similar to its existing production counterpart.”
當使用 TW-BERT 生成的術語權重時,這會導致檢索改進,同時保持 IR 基礎設施與其現有的對應產品相似。”
? ? ? ? ?
TW-BERT 算法為查詢分配權重,以提供更準確的相關性分數,然后排名過程的其余部分可以使用該分數。
? ? ? ? ? ? ?術語加權檢索 (TW-BERT)? ?
? ?術語加權檢索 (TW-BERT)? ?
 ?
?
TW-BERT 易于部署 ?
TW-BERT 的優點之一是它可以像一個插入組件一樣直接插入到當前的信息檢索排序過程中。
“這使我們能夠在檢索期間直接在 IR 系統中部署術語權重。這與之前的加權方法不同,后者需要進一步調整檢索器的參數以獲得最佳檢索性能,因為它們優化通過啟發式獲得的術語權重,而不是優化端到端。”這種易于部署的重要之處在于,不需要專門的軟件或硬件更新即可將 TW-BERT 添加到排名算法過程中。
Google 在其排名算法中使用 TW-BERT 嗎? ?
如前所述,部署 TW-BERT 相對容易。在我看來,可以合理地假設,部署的簡便性增加了該框架被添加到 Google 算法中的可能性。這意味著谷歌可以將 TW-BERT 添加到算法的排名部分,而無需進行全面的核心算法更新。
? ? ? ? ?
除了易于部署之外,在猜測算法是否可以使用時要尋找的另一個質量是該算法在改進當前技術水平方面的成功程度。有許多研究論文只取得了有限的成功或沒有任何改進。這些算法很有趣,但可以合理地假設它們不會進入谷歌的算法。令人感興趣的是那些非常成功的,TW-BERT 就是這種情況。
? ? ? ? ?
TW-BERT 非常成功。他們表示,很容易將其放入現有的排名算法中,并且其性能與“密集神經排名器”一樣好。
論文解釋了它如何改進當前的排名系統:
? ? ? ? ?
“Using these retriever frameworks, we show that our term weighting method outperforms baseline term weighting strategies for in-domain tasks.
“使用這些檢索器框架,我們表明我們的術語加權方法優于領域內任務的基線術語加權策略。
? ? ? ? ?
In out-of-domain tasks, TW-BERT improves over baseline weighting strategies as well as dense neural rankers.
在域外任務中,TW-BERT 改進了基線加權策略以及密集的神經排序器。
? ? ? ? ?
We further show the utility of our model by integrating it with existing query expansion models, which improves performance over standard search and dense retrieval in the zero-shot cases.
我們通過將模型與現有的查詢擴展模型集成來進一步展示模型的實用性,這在零樣本情況下提高了標準搜索和密集檢索的性能。
? ? ? ? ?
This motivates that our work can provide improvements to existing retrieval systems with minimal onboarding friction.”
這促使我們的工作能夠以最小的基礎來改進現有的檢索系統。”
? ? ? ? ?
這就是 TW-BERT 可能已經成為 Google 排名算法一部分的兩個充分理由。
? ? ? ? ?
1.這是對當前排名框架的全面改進
2.易于部署
? ? ? ? ?
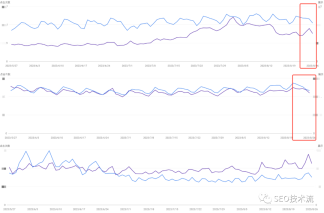
如果 Google 部署了 TW-BERT,那么這可能可以解釋 SEO 監控工具和搜索營銷社區成員在過去一個月報告的排名波動。一般來說,谷歌只會宣布一些排名變化,特別是當它們造成明顯影響時,例如谷歌宣布 BERT 算法時。在沒有官方確認的情況下,我們只能推測 TW-BERT 是 Google 搜索排名算法一部分的可能性。
? ? ? ? ?
盡管如此,TW-BERT 是一個了不起的框架,它似乎提高了信息檢索系統的準確性,并且可以被谷歌使用。
翻譯整理作品, 原文作者:Roger Montti
文章中提到的論文原文在這里:https://marc.najork.org/pdfs/kdd2023-twbert.pdf
? ? ? ? ?
文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)