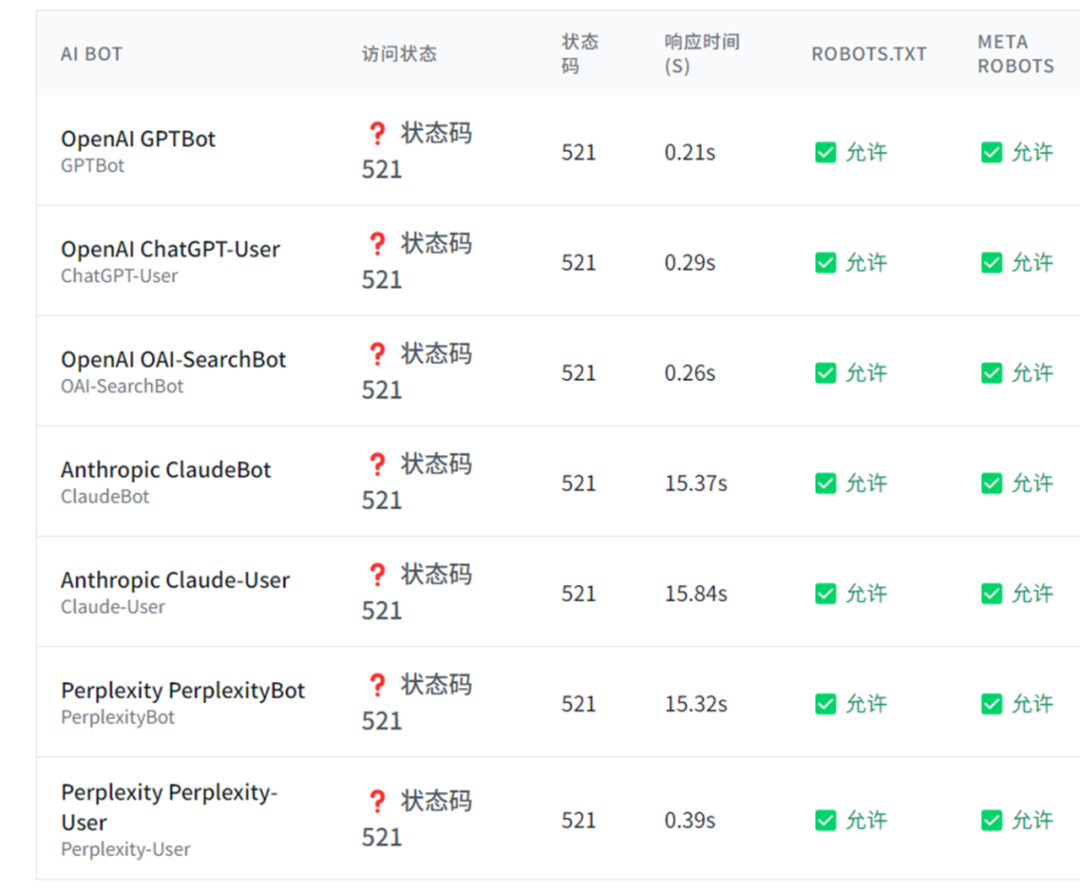
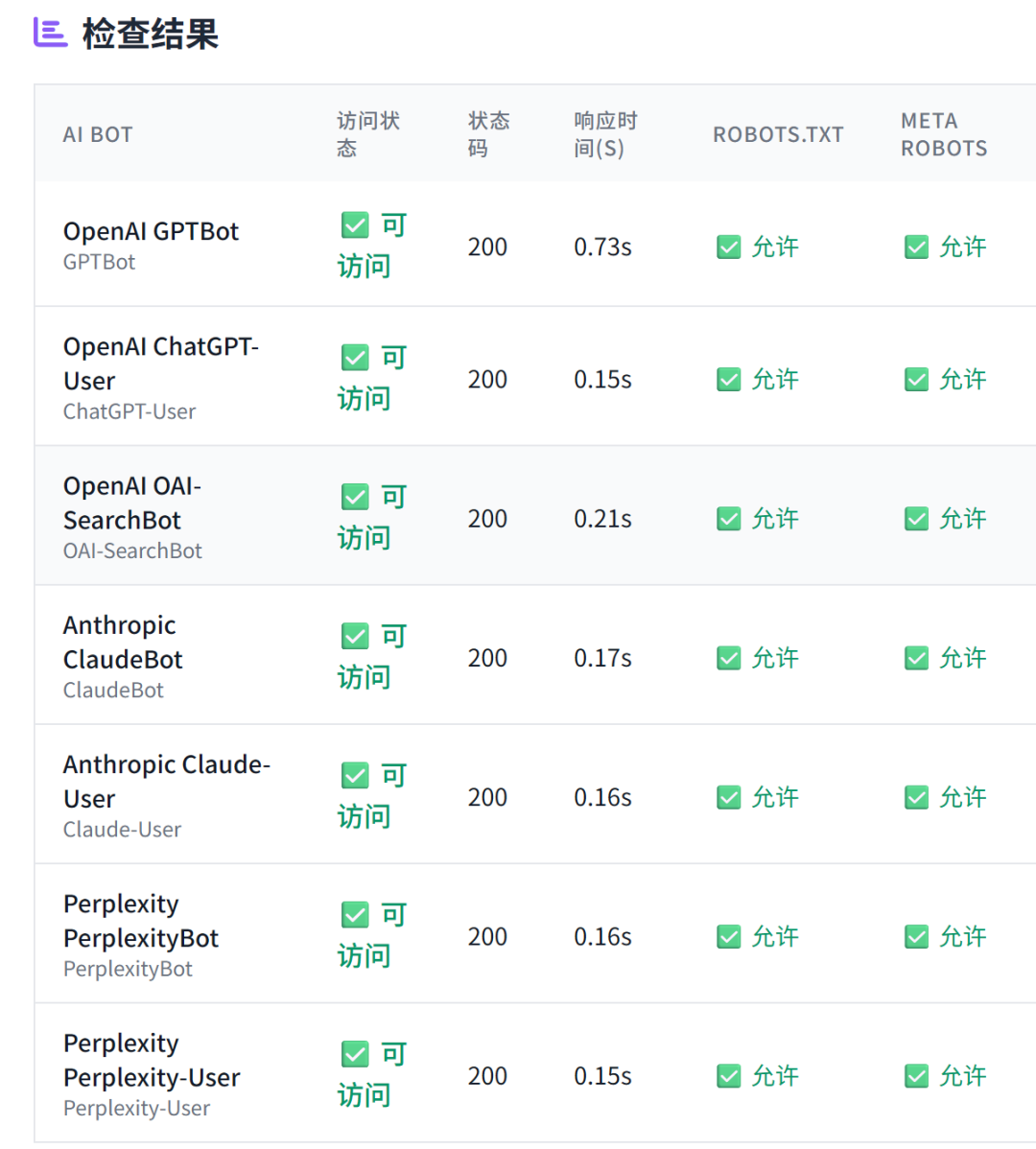
SEO 進化成 GEO 已經成為行業共識,而 GEO 優化的第一步,就是 AI 爬蟲能否正常抓取網頁內容。 對于中大型網站,通常有多層安全系統,除了常規的 robots.txt 文件外,還有 CDN、服務器防火墻、速率限制系統、地理限制等防護措施。因此,使用本工具來檢驗 AI bot 是否正常抓取,是非常有必要的。 AI 爬蟲抓取驗證工具,主要檢查 AI 爬蟲在抓取網頁時是否正常,不僅檢查 robots.txt、Meta Robots的設置,還會實際模擬 AI bot 來抓取網頁,且展示抓取到的 Title 內容,來全方位驗證 AI 爬蟲的抓取是否正常。 工具地址:https://www.bestwaytool.com/AIbots_checker/ (也可以點擊公眾號下方的“閱讀原文”)。 該工具可免費使用,如果您覺得好用,歡迎分享和推薦給朋友。 上圖就是群友使用工具測出來的抓取異常情況。 正常情況是: 模擬主流的 AI Bot 進行訪問,包含以下 AI 爬蟲: 不僅如此還會分析抓取時的狀態: 問:為什么需要檢查AI爬蟲訪問? 答:現代大型網站通常采用多層安全系統。即使AI爬蟲在robots.txt中被明確允許,它們仍可能在其他級別被阻止,如CDN級別阻止、防火墻規則、頻率限制系統等。這造成了預期政策與實際訪問之間的差距。所以檢查AI爬蟲訪問,可以全方位分析 AI 爬蟲抓取是否正常。 問:檢查結果中的狀態碼代表什么? 答:200表示可訪問,403表示被阻止,429表示頻率限制,404表示頁面不存在。這些狀態碼幫助您了解AI爬蟲訪問您網站時的具體遭遇。 問:robots.txt和meta robots標簽有什么區別? 答:robots.txt是網站根目錄下的文件,用于指導所有爬蟲的訪問規則;meta robots標簽是HTML頁面中的標簽,用于控制特定頁面的索引和爬取行為。兩者都很重要,需要配合使用。 問:如何根據檢查結果優化網站? 答:如果發現AI爬蟲被意外阻止,可以檢查CDN設置、防火墻規則、頻率限制等;如果希望AI爬蟲訪問,確保robots.txt和meta標簽設置正確;如果希望阻止,可以明確設置相應的阻止規則。

功能簡介
操作步驟
常見問答
文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)






