
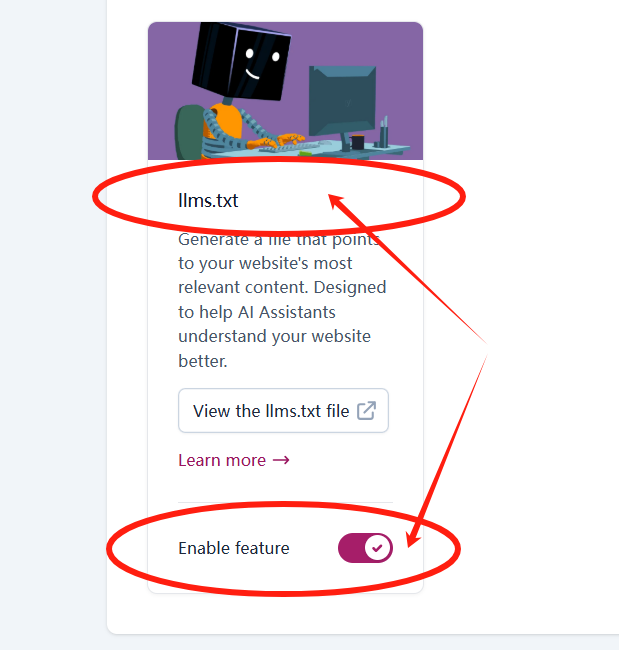
llms.txt?標準的提出旨在解決一個根本性挑戰:大型語言模型(LLM)難以高效地解析標準網頁,這些網頁通常充斥著與核心內容無關的 HTML、JavaScript、CSS 和廣告?
為應對此問題,Answer.AI 的 Jeremy Howard 于 2024 年 9 月首次提出了一項解決方案:引入一個簡單、結構化的純文本 Markdown 文件(/llms.txt),作為 AI 的“備忘單”或“發現指南”?
主要 AI 開發商的官方對 llms 的評價
-
谷歌 (Gemini):谷歌的 John Mueller 態度明確。他在 Bluesky 上表示:“僅供參考,目前沒有任何 AI 系統使用 llms.txt”?
??它們中沒有一個會去抓取 llms.txt 文件 ”??keywords ?元標簽??? 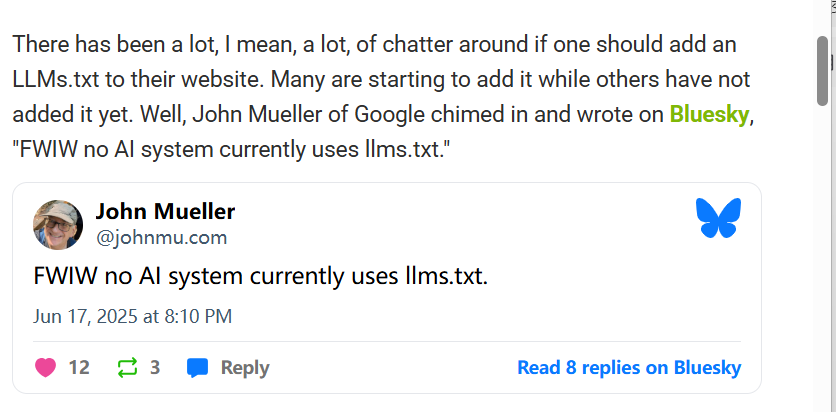
-
OpenAI (ChatGPT):OpenAI 為其爬蟲(如?
GPTBot、ChatGPT-User)發布的官方文檔中并未提及?llms.txt。ChatGPT官方文檔只詳細地說明了如何使用?robots.txt?來授予或拒絕訪問??? Anthropic (Claude):同樣,Anthropic 為其爬蟲(如?
ClaudeBot、Claude-User)發布的文檔也詳細說明了通過?robots.txt?進行控制,甚至提到了非標準的?Crawl-delay?指令,但完全沒有提到?llms.txt使用 了?llms.txt?文件?
llms.txt 不是AI的靈丹妙藥,核心還是要關注內容本身的質量
-
專注于內容質量和結構。為人類編寫清晰、組織良好的內容。使用正確的 HTML 標題(H1, H2 等)、列表和結構化數據(Schema.org)。這使得內容對人類和 AI?都更容易解析,是比依賴一個單獨文件遠為有效的策略?
?? -
?
llms.txt?照樣添加上,但不要花太多精力既然Yoast能輕松搞定,那肯定還是把他添加上,總之沒有壞處,有沒有AI流量的好處,還不知道。 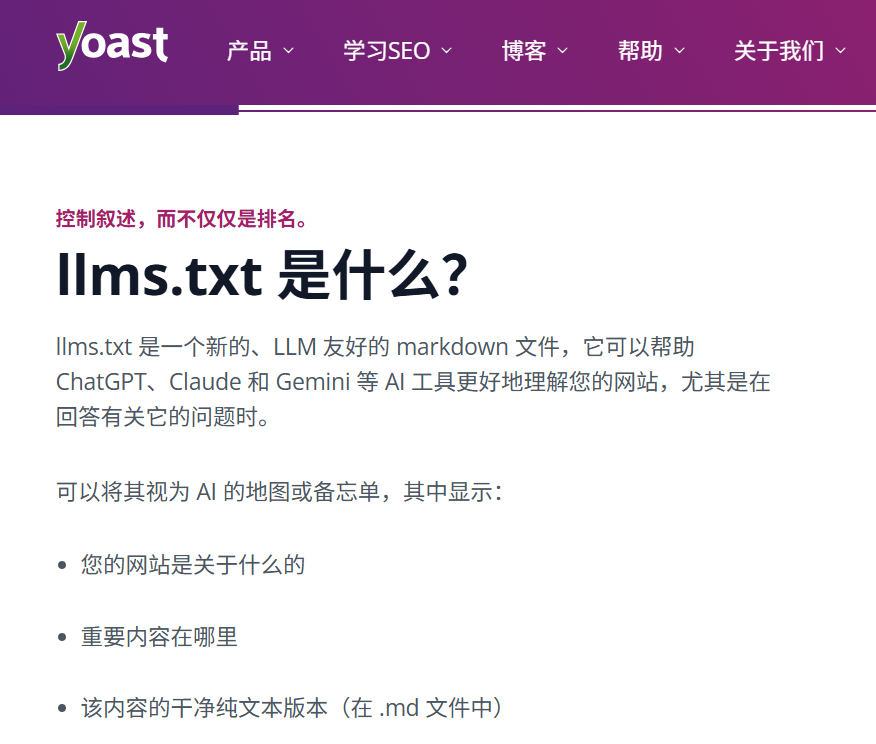
以往的文章也是干貨,歡迎閱讀和轉發
谷歌算法又雙叒叕更新?Google SEO算法為啥一直在更新?
文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)






