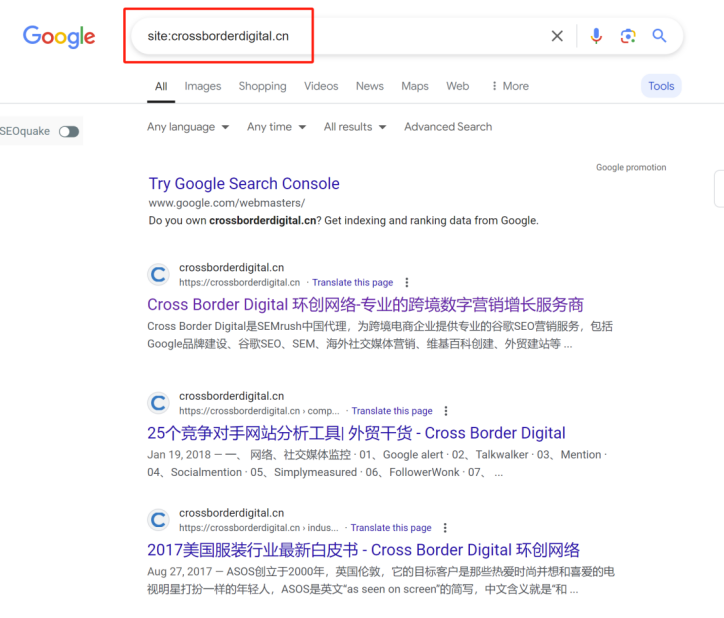
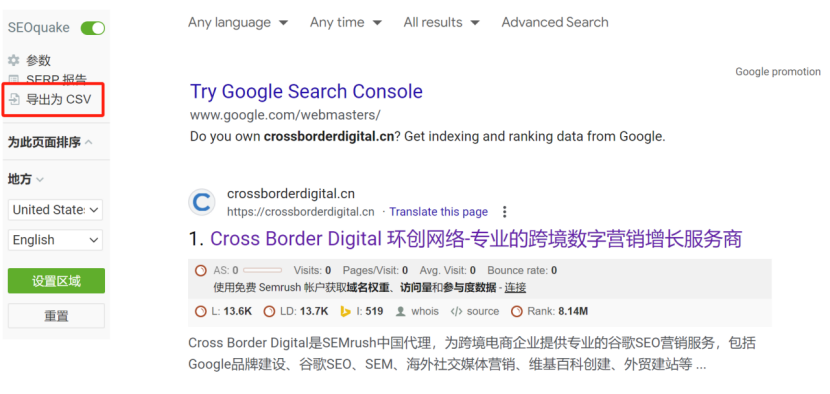
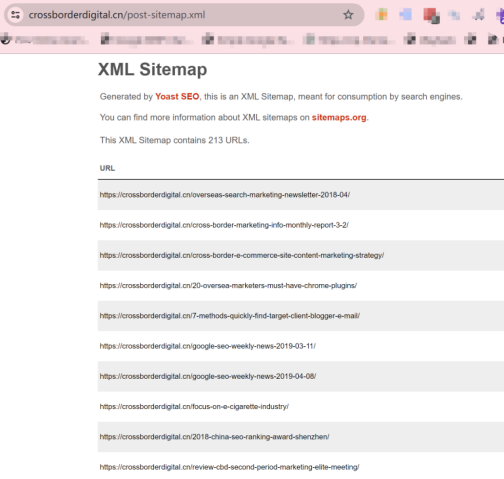
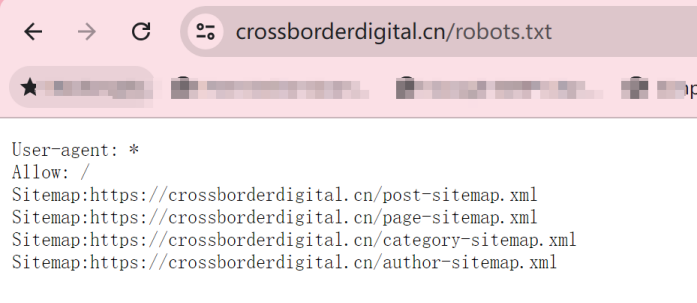
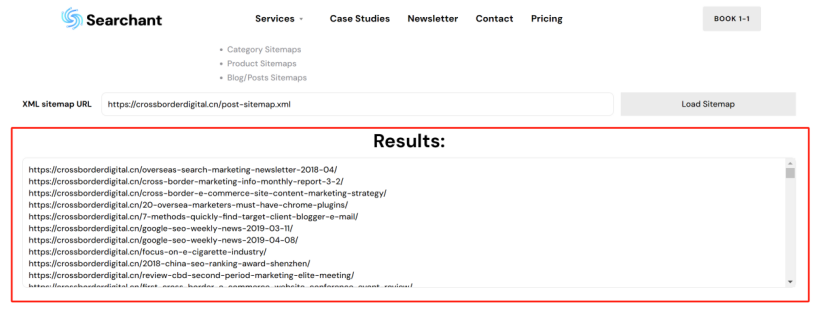
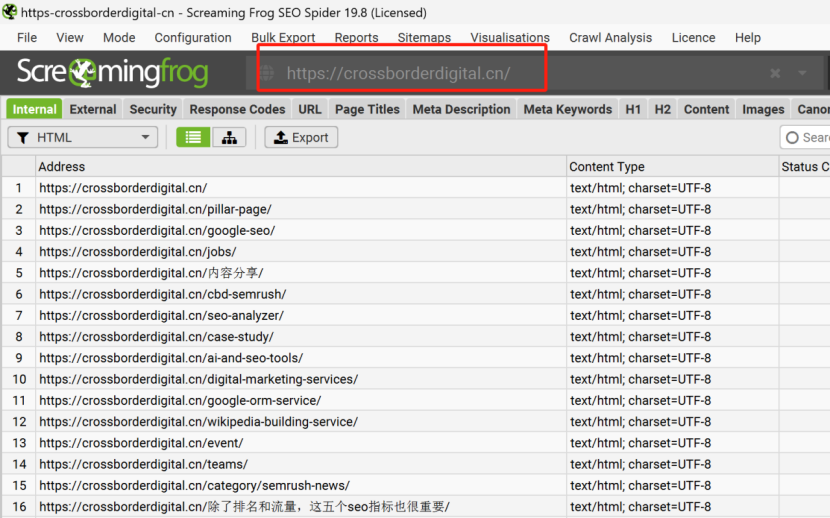
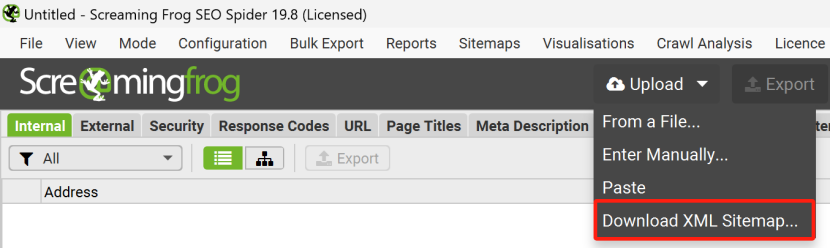
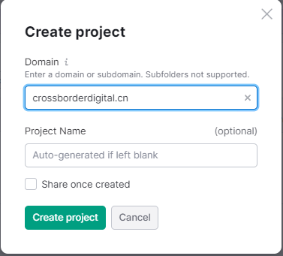
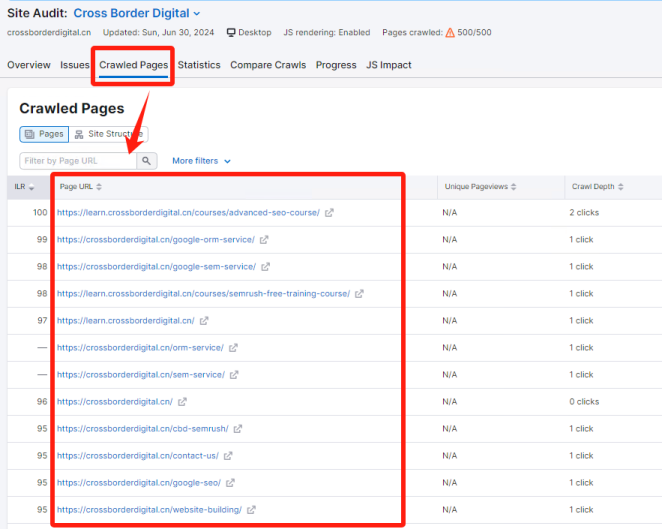
是否有辦法了解競品的網站規模大小,存在多少有效頁面,從而進行更加詳細的內容差距分析呢? 如果能夠獲得這些信息,就能夠將自己與競品的網站規模進行對比分析,了解與競品網站之間的內容量差距,競品在哪類內容上投入了更多的資源,以及競品的網站架構是怎么樣的,甚至還有機會洞察競品的內容策略。 所有的這些洞察,前提都是先要獲得競品網站的所有有效頁面URL,從更全局的角度來對比分析。 但是手動從競品網站中逐個復制頁面URL,肯定不是一個有效的解決方案。 因此,我們可以借助不同的工具,來快速整理出競品網站的所有有效頁面URL。 下面就介紹四種不同的方式,來實現這個目的。 在谷歌搜索中,使用Site命令,可以找到競品網站中大量被收錄的頁面。 如下圖所示(site: domain.com),谷歌會將查詢網站中的收錄頁面羅列出來。 (使用Site命令找出目標網站被收錄的頁面) 這種方式最大的優勢是: 免費 簡單易用 快捷 而劣勢也很明顯: 頁面數據不全(因為谷歌只收錄了它覺得有價值的頁面,因此并未包含所有頁面) 導出數據不方便(雖然可以借助瀏覽器插件,例如SEOquake,來導出頁面數據,但如果頁面量級大的話,還是比較麻煩) (使用SEOquake插件來導出頁面URL) 第二種方式,則是直接從網站的站點地圖中收集頁面URL數據。 通常而言,我們會把網站中所有的重要頁面都放到XML Sitemap中,方便搜索引擎抓取收錄。 (XML Sitemap中的URL示例) 因此,通過提取XML Sitemap中的頁面URL數據,我們可以快速且有效地實現這個目的。 默認網站的XML Sitemap會放在網站的根域名下,例如:https://www.domain.com/sitemap.xml。 如果在根域名下沒找到的話,也可以到網站的robots.txt文件中找一下。 因為通常會在robots.txt文件中聲明XML Sitemap所在的路徑,來引導搜索引擎抓取站點地圖。 (robots.txt文件中sitemap地址示例) 這樣,我們就可以使用免費工具(例如https://www.searchant.co/sitemap-tool),來將XML Sitemap的頁面URL快速提取出來了。 只需要輸入競品網站的XML Sitemap地址,等待片刻,就能直接導出頁面URL數據。 (使用Searchant來提取Sitemap中的頁面URL) 這種方式的優勢在于: 免費 方便快捷 獲取到所有重要頁面 而劣勢則是: 需要競品網站已生成XML Sitemap 且能夠找到正確的XML Sitemap位置 Screaming Frog Screaming Frog(尖叫青蛙)是一款專門用來抓取網站頁面數據的爬蟲工具,非常強大,用它來抓取網站頁面URL數據簡直是輕而易舉。 我們之前也專門寫過一篇公眾號文章:《Screaming Frog,讓你尖叫著提升效率》,全方位的分享了我們是如何在SEO工作中使用Screaming Frog來抓取網站信息,提升效率的。 使用Screaming Frog來抓取網站頁面URL非常簡單,只需要在上方地址柆中輸入競品網站URL,等待它完成抓取,導出即可! (使用Screaming Frog來抓取網站頁面信息) 當然,如果覺得抓取整個網站太慢,也可以僅抓取XML Sitemap中的頁面URL。 切換抓取模式為List Mode,然后將競品網站的XML Sitemap地址粘貼進去,等待抓取完成。 (切換至Screaming Frog的List抓取模式) 這種方式的優勢主要是: 方便快捷 抓取效率高 多種抓取方式可用 抓取到的網站頁面URL完整 額外獲得更多頁面信息數據(例如Title,Description內容) 而劣勢則是: 付費工具(折合約1800+RMB/年) 有一丟丟的學習成本 Semrush 通過在Semrush中創建專門的Project,并設置Site Audit后,也能找到競品網站的所有頁面URL。 (在Semrush中創建Project) 等待Semrush抓取完所有頁面后,我們就能夠在Crawled Pages中,找到競品的所有網站頁面URL信息。 (在Semrush中找到所有被抓取的頁面) 點擊右上角的Export按鈕,可以導出所有的頁面URL數據。 (導出被抓取的頁面) 使用Semrush的優勢主要有: 方便快捷 抓取效率高 抓取到的網站頁面URL完整 額外獲得更多頁面信息數據 而唯一劣勢則是: 付費工具 小結 如果只是希望簡單獲取競品網站的頁面URL,前兩種免費方式就夠用了。 但如果是希望能夠獲取到更多的頁面信息和數據洞察,Semrush則更加合適。 推薦大家觀看《如何利用Semrush分析與競品的內容差距》的視頻講解,助你快速找到更多的內容主題機會。
谷歌Site命令
XML Sitemap



文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)






