親愛的梨粉們,看這里吖!!! 一定要將公眾號?設為“星標”?哦~這樣就再也不怕錯過我的任何消息啦。 我是超級愛碼字的雪梨寶寶:外貿新秀,業界卷王。 每天8:00準時給大家推送最專業最全面的外貿干貨文章? 更多精品文章請查看博客shelleydigital.com

1?feed
2?圖片鏈接
3?內容分頁
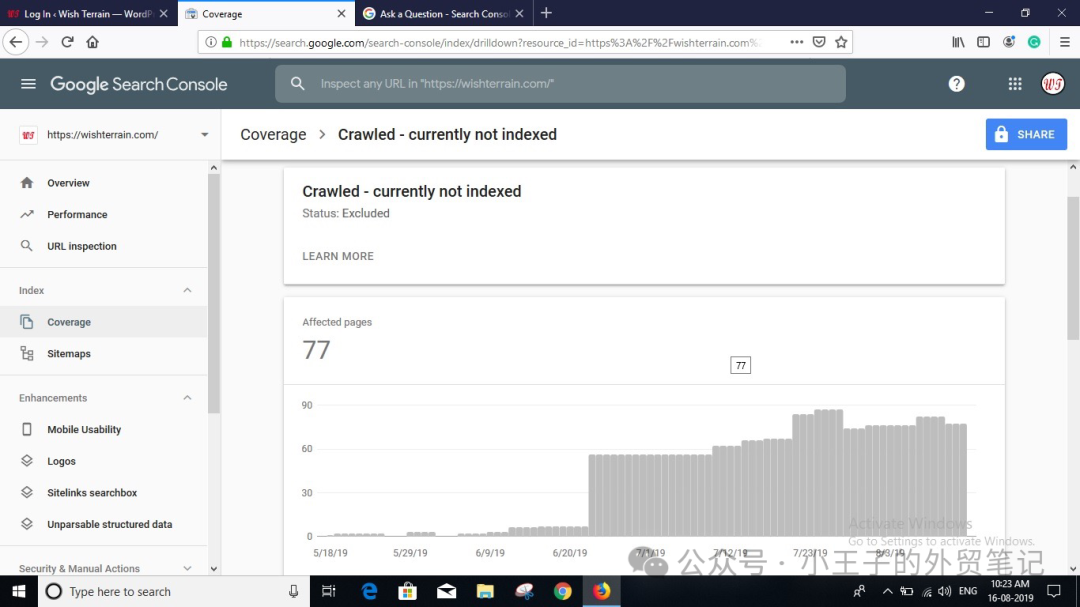
“已抓取 - 當前未編入索引”另一個極其常見的原因是與分頁相關。
分頁 URL 是在末尾帶有代表頁面的數字的頁面,例如,www.mydomain.com/blog/page/2。我們經常會在該報告中看到大量分頁 URL 的存在:
為了完整抓取網站內容,谷歌需要抓取分頁 URL。這是谷歌獲取網站內容的途徑。然而,盡管谷歌使用分頁作為訪問內容的途徑,但并不一定需要對分頁 URL 進行索引。
這種情況不用處理。
4?內容薄弱以及低質
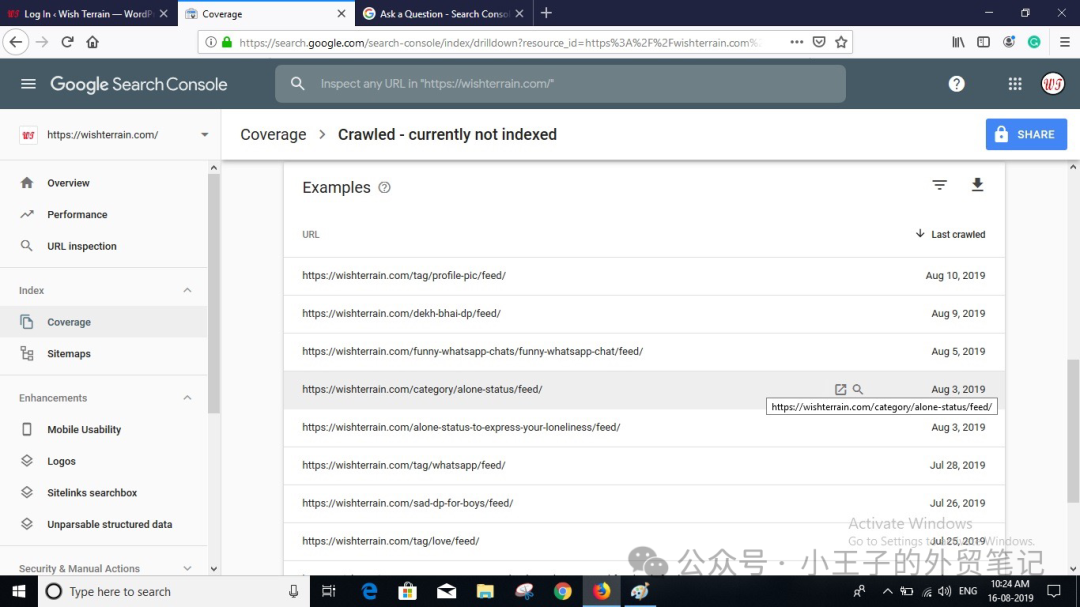
有時候我們會看到這份報告中的URL內容非常有限,甚至只是堆積了低質量的文字。這些頁面可能已經正確設置了所有技術元素,甚至可能有正確的內部鏈接,但是當Google訪問這些URL時,頁面上的實際內容非常有限或質量低下,以至于Google認為它們沒有太多用處。
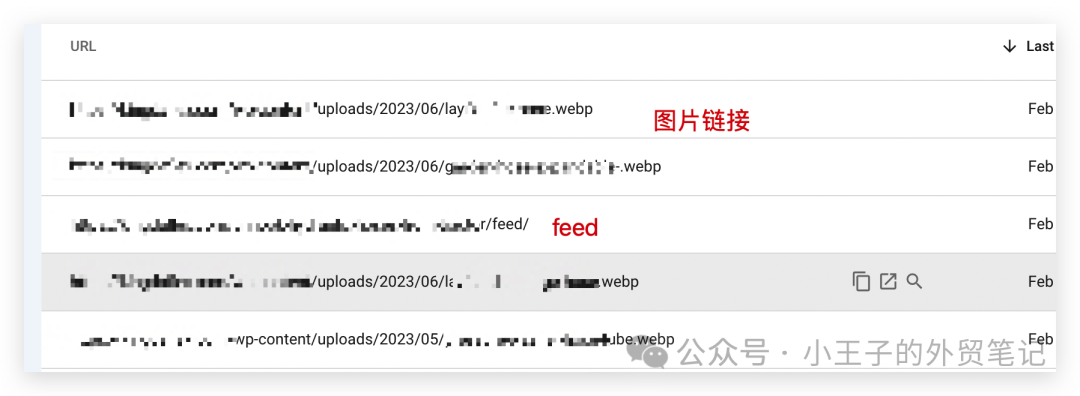
如果你注意到“已抓取 – 當前未編入索引”中列出的大多數都是內容分頁、RSS Feed以及其他內容非常稀少的雜項頁面,那么你可以理解為這些頁面并未為用戶提供足夠的價值,因此Google沒有編入它們的索引也就可以理解了。如果確實是這種情況,那么你可以忽略這些頁面。
但是,如果你看到你網站上很多重要頁面(包含有價值/有用信息)被列在這里,那可能是整個站點范圍內的質量問題影響了你的重要頁面被編入索引。
優先級:高
解決方案:
作為網站所有者,你應該確保你的頁面提供高質量的內容。檢查它是否能夠滿足用戶的意圖,并在需要時添加高質量的內容。Google提出了一系列問題來幫助你確定內容的價值:
內容是否提供了原創的信息、報告、研究或分析?
內容是否提供了對主題的實質性、完整性或全面性描述?
內容是否提供了富有洞察力的深刻見解或有趣信息?
如果內容借鑒了其他來源,它是否避免了簡單地復制或改寫那些來源,而是提供了實質性的額外價值和原創性內容?
標題和/或網頁標題是否對內容進行了非常實用的描述性總結?
標題和/或網頁標題是否避免了夸大其詞或聳人聽聞?
您會將這種網頁添加為書簽、分享給朋友或推薦給他人嗎?
您覺得這樣的內容會出現在印制的雜志、百科全書或書籍中或被它們引用嗎?
另一個需要關注的方面是優化網站上用戶生成的內容。例如,假設您有一個論壇,有人問了一個問題。盡管將來可能會有很多有價值的回復,但在抓取時沒有回復,因此Google可能會將頁面歸類為低質量內容。
此外,您還可以通過系統地從索引中刪除低質量頁面來提高整體站點質量。然而,網站質量并不是一夜之間就能改變的。谷歌需要一段時間來接收信號、重新處理和重新評估您的整體網站質量。
5?重復內容
“內容重復”指的是網站上存在相似或相同的內容,這可能發生在同一網站的不同頁面之間,也可能發生在不同網站之間。內容重復可能對搜索引擎排名產生負面影響,因為搜索引擎通常傾向于提供多樣性和獨特性的搜索結果。
內容重復可以分為兩種主要類型:
內部內容重復:發生在同一網站內的不同頁面之間。這可能是因為網站有多個URL指向相同或幾乎相同的內容,導致搜索引擎難以確定哪個頁面是最相關的。
解決方法:使用規范標簽(Canonical Tag)指定主要版本,確保內部鏈接指向規范版本,從而告訴搜索引擎哪個是原始內容。
外部內容重復:發生在不同網站之間,其中一些內容與其他網站上的內容相似或相同。這可能是意外的,也可能是惡意的抄襲行為。
解決方法:對于外部內容重復,網站所有者可以聯系相關方,請求刪除或修改重復內容。此外,通過提供原創和有價值的內容,網站可以在搜索引擎中獲得更好的排名。
為避免內容重復問題,網站管理員可以采取以下措施:
創建獨特的、有價值的內容,吸引用戶和搜索引擎。
使用301重定向來將不同版本的URL指向主要版本。
在站點地圖中只包含規范版本的頁面。
定期監控Google Search Console以檢測重復內容問題。
使用合適的規范標簽來明確原始內容。
通過避免內容重復,網站可以提高搜索引擎排名,提升用戶體驗,并降低被搜索引擎降權的風險。
6?已抓取– 尚未編入索引” vs. “已發現– 尚未編入索引”

了解在Google Search Console中“已抓取– 尚未編入索引”和“已發現– 尚未編入索引”這兩種狀態之間的區別對于有效的SEO管理至關重要。
已抓取– 尚未編入索引:
這個狀態表示Google的爬蟲已經訪問(抓取)了您的網頁并分析了其內容,但最終決定不將其包含在搜索索引中。這個決定可能是由于各種原因,如內容質量、網站架構問題或頁面不符合Google的指南。抓取過程意味著Google已經完全了解頁面上的內容,但選擇目前不在搜索結果中顯示它。
已發現– 尚未編入索引:
另一方面,“已發現– 尚未編入索引”狀態表示Google知道頁面的存在,通常是因為URL在XML站點地圖中被發現或從另一個站點鏈接過來。
然而,Google的爬蟲尚未訪問頁面以抓取其內容。這可能是由于各種因素,如抓取預算限制或Google爬取隊列中的積壓。在這種情況下,Google需要更多關于頁面內容的信息,只有在進行抓取后才能將其編入索引。
了解這些差異對于診斷和解決URL編入索引的問題至關重要。
對于標記為“已抓取– 尚未編入索引”的頁面,重點應放在提升頁面的內容和結構上。
對于狀態為“已發現– 尚未編入索引”的頁面,通常只需要等待Google的抓取。
然而,檢查頁面的可訪問性并確保它包含在站點地圖中可以加速這個過程。
以上。
往期推薦

歡迎大家私信獲取《谷歌SEO頁面優化清單》
文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)






