這幾天有跟朋友在討論,關于谷歌搜索引擎不收錄網站內容的問題,以及相應的一些解決方案。那今天這篇文章就簡單的梳理一下相關的邏輯,并分享一點我們自己的做法。
首先是怎么收錄的問題,即要不要手動提交申請收錄。
其實谷歌搜索引擎爬蟲是會定期光顧網站內容的,并且在網站的站點地圖上,有一個 LastMod 字段是能夠記錄網站最新內容的更新時間的。所以理論上是不需要我們再單獨手動,在谷歌站長工具里面提交我們的收錄申請。
但是按照我們自己的經驗,被動等待這種方式,最快也需要 2-3 天才能被爬蟲發現并收錄,遠不及主動提交方式來得快(最快 2-3 小時)。
所以處于收錄速度與數據統計便利的角度出發,還是建議在內容上線后采用手動提交的方式,去請求內容收錄。不過要注意的是,大部分谷歌站長賬戶的請求數量是有限制的(每天 10 條左右)。
但是無論是采用主動還是被動的收錄方式,都會存在一個問題,即網站的內容不被谷歌搜索引擎收錄。比如下圖便是我的一個新站數據,記錄著鏈接不被收錄的原因。
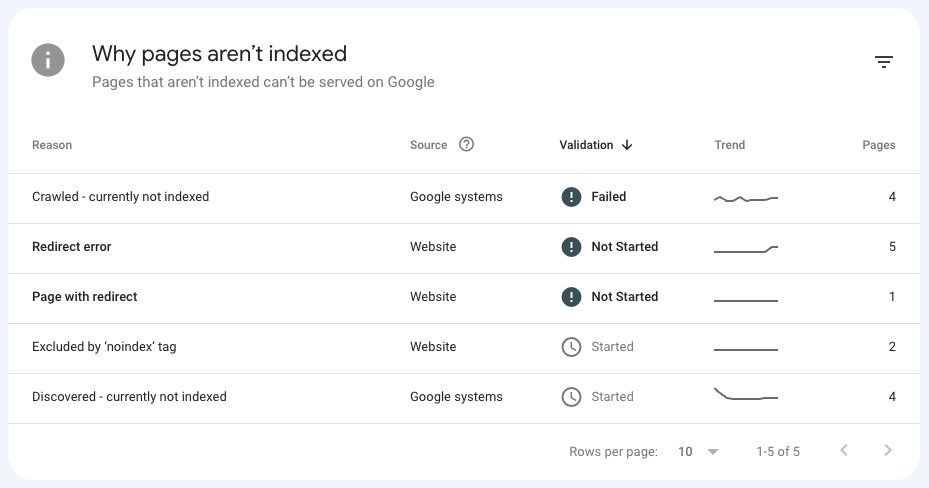
像“redirect error”,“noindex”這種技術類的問題是很好解決的,難的就是這種“currently not indexd”問題,根本不知道從哪里下嘴。
因為從我們站長的角度出發,都是采用相同手段寫的文章,也都是相同時間段提交的內容,但就是會存在有幾個內容不被收錄的概率。要么是“Discovered(已經發現內容)”不被收錄,要么是“Crawled(已經抓取內容)”不被收錄。
其實針對這些問題,去閱讀官方指導手冊,根本看不出門道來。手冊里面大多都是一個指導性的官話,要么內容重復,要么內容質量低下。
讓我們自查自糾的話,很難下手。
那這里分享兩個我們團隊在用的,解決這類問題的兩個小方法。
方法一是“等”,其實有時候那些“Discovered - currently not indexd”問題,可能是因為分配給網站的爬蟲抓取資源有限,導致沒有更多的爬蟲去處理這塊內容。
那針對這種問題,我們可以先等幾天看看谷歌搜索引擎是不是會收錄。按照我自己的經驗,基本上等幾天再重新手動提交一遍收錄,就能解決問題。另外還可以使用內鏈的方式去做這種內容的收錄,邏輯就是在新內容里加一條內鏈了,比較簡單。
但是對于“Crawled - currently not indexd”問題,再次提交收錄基本沒用。因為從技術角度出發,這個階段谷歌搜索引擎已經抓取了你的內容,只不過因為內容質量可能存在問題,導致最終沒有收錄。
所以要么你花大量精力去更改內容,使其符合谷歌搜索引擎的標準(說實話這個標準沒辦法量化,挺虛無縹緲的)。也正是基于此點,這種直接修改內容的方式,我基本很少使用。
所以如果可以的話,考慮下修改文章的標題并修改文章的鏈接地址信息,將那條不收錄的內容包裝成一個“新”內容,再去請求收錄,80% 的概率能通過,就是這么魔幻。
以上,一點關于收錄問題的分享。

文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)






