我在上一篇關(guān)于谷歌技術(shù)SEO的文章中分享了一段這樣的經(jīng)歷:在發(fā)現(xiàn)一個(gè)幾乎沒有熱度和頁面權(quán)威度的網(wǎng)頁沒有被收錄后,我通過把網(wǎng)頁加入到XML Sitemap中這樣一個(gè)簡(jiǎn)單的動(dòng)作,在兩天內(nèi)實(shí)現(xiàn)了被收錄。
過去也被不少人問過:新網(wǎng)頁沒有被收錄,和舊頁面做了優(yōu)化后遲遲不見搜索引擎同步更新之類的問題,所以在這篇文章,就來說說常見的導(dǎo)致網(wǎng)頁不被Google收錄的原因和如何去解決它。
內(nèi)容有點(diǎn)多,所以我用思維圖整理了這個(gè)話題的重點(diǎn),方便大家快速 、系統(tǒng)地進(jìn)行了解:
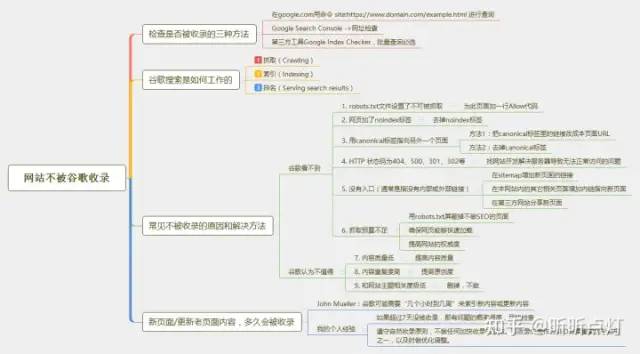
一. 檢查網(wǎng)站是否被收錄的三種方法
沒有收錄,就沒有排名可言,具體邏輯在后面的第二大點(diǎn)關(guān)于谷歌搜索引擎是如何工作的有講到。
一般我們發(fā)現(xiàn)頁面沒有SEO排名和流量,就會(huì)第一時(shí)間去檢查該頁面是否被谷歌收錄了。我常用的三種檢查收錄的方法:
site命令
在http://google.com用命令 site:https://www.domain.com/example.html?進(jìn)行搜索查詢。如果有返回正確結(jié)果,就代表已經(jīng)收錄了。
注意:site指令不會(huì)顯示所有相關(guān)結(jié)果。如果你發(fā)現(xiàn)存在site命令沒有返回正確結(jié)果但是Google Search Console卻顯示已編入索引的情況,可以參考我在另外一篇文章“用site命令查到頁面沒被收錄/索引頁數(shù)少于谷歌網(wǎng)站管理員工具中報(bào)告的頁數(shù),怎么辦?”中關(guān)于這個(gè)問題的優(yōu)化思路。
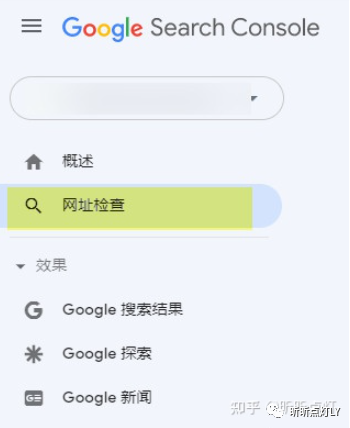
2.?Google Search Console的網(wǎng)址檢查工具。見下圖:
3.?第三方Google索引檢查工具。
前面兩種方式都只能每次查詢一個(gè)頁面,用第三方工具的好處是可以實(shí)現(xiàn)批量查詢。Google一下“Google Index Checker”,可以找到很多在線檢查收錄的工具。
如果不幸地,你通過以上的方式查出你的頁面沒有被收錄,那希望下面的解決方案能夠幫助到你實(shí)現(xiàn)頁面被Google收錄。
二. 谷歌搜索引擎是如何進(jìn)行頁面抓取、索引和排名的
知乎上也有不少關(guān)于網(wǎng)站內(nèi)容沒有被收錄問題的解答,但是很少會(huì)講到搜索引擎是如何工作的。我認(rèn)為大家很有必要知道,因?yàn)?span style="font-synthesis: style;font-weight: 600;">當(dāng)你通過學(xué)習(xí)搜索引擎工作原理去理解了網(wǎng)頁不被收錄的本質(zhì),你就擁有了能夠快速地化解所有不被收錄問題的能力。
讓網(wǎng)頁出現(xiàn)在谷歌搜索結(jié)果中需要經(jīng)歷三個(gè)階段:
階段1:抓取(Crawling)
抓取也經(jīng)常被稱為“爬行”。谷歌會(huì)使用一種自動(dòng)程序從互聯(lián)網(wǎng)上發(fā)現(xiàn)各類網(wǎng)頁,并下載其中的文本、圖片和視頻,這個(gè)程序經(jīng)常被稱作“蜘蛛”、“機(jī)器人”或“爬蟲”(都是指同一個(gè)東西)。
推廣經(jīng)常會(huì)看到的兩種谷歌蜘蛛:應(yīng)用在SEO工作上的Googlebot,和應(yīng)用在廣告工作上的GoogleAdsBot。
為了讓你的內(nèi)容顯示在 Google 搜索上,必須首先確保你的網(wǎng)站可以被 Google 的 Googlebot 抓取工具抓到。
階段2:索引(Indexing)
Google 會(huì)分析網(wǎng)頁上的文本、圖片和視頻文件,并將信息存儲(chǔ)在大型數(shù)據(jù)庫(kù) Google 索引中。
不是所有被抓取的頁面都被會(huì)索引。
階段3:呈現(xiàn)搜索結(jié)果(Serving search results)
當(dāng)用戶在 Google 中搜索時(shí),Google 會(huì)返回與用戶查詢相關(guān)的信息。
不是所有被索引的頁面都會(huì)有排名。
基于以上,如果你的網(wǎng)站沒有被收錄,那原因只會(huì)是下面兩點(diǎn):
谷歌看不到
谷歌認(rèn)為不值得
三. 常見的網(wǎng)站/網(wǎng)頁不被谷歌收錄的原因和解決方法
首先來說說因?yàn)楣雀杩床坏綇亩鵁o法被抓取的6種常見的情況:
1. robots.txt設(shè)置了不可被抓取
robots文件告訴了搜索引擎要抓取哪些網(wǎng)頁和不要抓取哪些網(wǎng)頁。
檢查你的robots文件中disallow部分代碼,看看不被收錄的網(wǎng)頁是不是觸發(fā)了disallow規(guī)則。
比如我們來看anker的robots.txt, 它禁止了谷歌去爬URL中帶有/coming-soon的網(wǎng)頁。也就是說,如果你的網(wǎng)頁URL是https://www.anker.com/coming-soon/power-adapter,那通常(非絕對(duì))谷歌就不會(huì)去爬它。
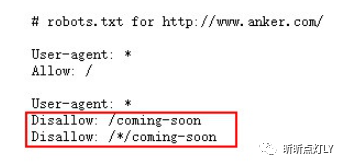
最快的解決方法是在robots文件中加一行Allow代碼:
Allow:?https://www.anker.com/coming-soon/power-adapter(要谷歌被爬行的網(wǎng)址)
2. 網(wǎng)頁HTML代碼加了noindex標(biāo)簽
noindex標(biāo)簽的作用是告訴搜索引擎不要去索引該頁面。
檢查方法:頁面右擊->查看網(wǎng)頁源代碼->搜“noindex”, 如果你發(fā)現(xiàn)有以下這行代碼:
<meta name="robots" content="noindex,nofollow" />
那你要做的就是去掉這行代碼。
3. canonical標(biāo)簽指向另外一個(gè)網(wǎng)頁
canonical標(biāo)簽是為了解決網(wǎng)址規(guī)范化問題,告訴搜索引擎那個(gè)網(wǎng)址才是最重要的。
網(wǎng)頁可以不帶canonical標(biāo)簽。我發(fā)現(xiàn)很多網(wǎng)站的頁面都會(huì)帶上canonical標(biāo)簽, 鏈接指向本頁面;如果鏈接指向非本頁面, 那谷歌很多時(shí)候(非絕對(duì))就不會(huì)抓取該頁面。
檢查方法:頁面右擊->查看網(wǎng)頁源代碼->搜“canonical”,如果canonical標(biāo)簽里的鏈接不是本頁面的URL,那你要做的就是把鏈接改成本頁面的URL,或者直接去掉canonical這行代碼。
4. HTTP 狀態(tài)碼為404、500、301、302
托管站點(diǎn)的服務(wù)器在響應(yīng)搜索蜘蛛爬蟲發(fā)出的請(qǐng)求時(shí)會(huì)生成HTTP狀態(tài)碼。
我們經(jīng)常遇到的會(huì)造成搜索爬蟲無法抓取頁面的HTTP狀態(tài)碼是404、500、301和302。
如果打開網(wǎng)頁,發(fā)現(xiàn)返回了以上狀態(tài)碼提示,無法訪問,那你要做的是去找網(wǎng)站開發(fā)人員去處理。
正常能讓搜索引擎爬蟲和用戶訪問的頁面的狀態(tài)碼是200。
5. 沒有入口(通常是指沒有內(nèi)部或外部鏈接)
蜘蛛在工作時(shí)通常從一個(gè) URL 開始,然后從順著爬到其它URL。如果你的頁面是孤立的,那就很難被蜘蛛爬到。因此,我們需要給搜索引擎蜘蛛一個(gè)引導(dǎo)。
以下是三種簡(jiǎn)單又快速增加入口的方式:
把鏈接加入到XML sitemap。
找到自己網(wǎng)站內(nèi)和此頁面內(nèi)容有相關(guān)聯(lián)的網(wǎng)頁,增加一個(gè)指向該頁面的內(nèi)鏈。
在第三方網(wǎng)站分享鏈接,比如Twitter,F(xiàn)acebook和一些RSS網(wǎng)站。
6. 抓取預(yù)算不足
谷歌有數(shù)千臺(tái)機(jī)器來運(yùn)行蜘蛛,但有一百萬個(gè)網(wǎng)站等待被抓取。因此,每個(gè)蜘蛛到達(dá)你的網(wǎng)站時(shí)都會(huì)有預(yù)算,也就是它們可以在你網(wǎng)站花費(fèi)的資源數(shù)量是有限的。
以下三種方法都可以提高抓取預(yù)算:
用robots.txt屏蔽掉不做SEO、也不會(huì)影響整站SEO排名的頁面。
確保網(wǎng)頁能夠快速加載。
提高網(wǎng)站的權(quán)威度。
以上就是常見的在搜索引擎第一階段工作時(shí)就遇到了阻礙導(dǎo)致到無法正常進(jìn)入索引的情景。
接下來講講因?yàn)楣雀栌X得頁面質(zhì)量不行從而不值得去收錄的三種常見情況。
7. 內(nèi)容質(zhì)量低
舉個(gè)極端的例子:一個(gè)頁面只有一行話,這種內(nèi)容極度薄弱的頁面, 是幾乎不可能通過谷歌的收錄。
沒什么捷徑可走,就是提高頁面內(nèi)容的質(zhì)量。
8. 內(nèi)容重復(fù)度高
舉個(gè)常見的例子 :你的網(wǎng)站轉(zhuǎn)載了一篇由行業(yè)內(nèi)名人撰寫的非常專業(yè)的文章,而且這篇文章也被很多其它網(wǎng)站轉(zhuǎn)載了,谷歌就會(huì)認(rèn)為這些網(wǎng)絡(luò)上大量重復(fù)的內(nèi)容對(duì)用戶來說是沒有價(jià)值的,故就不會(huì)去收錄。
沒什么捷徑可走+1,你要做的就是去提高內(nèi)容的原創(chuàng)度。
9. 和網(wǎng)站主題相關(guān)度極低
打個(gè)比方,你運(yùn)營(yíng)的是一個(gè)專業(yè)賣衣服的網(wǎng)站,突然增加一個(gè)關(guān)于教人如何做金融投資的頁面,主題差異相當(dāng)大。這個(gè)時(shí)候,谷歌就很可能會(huì)因?yàn)橄嚓P(guān)度不高而拒絕收錄。
對(duì)于這種情況,我的建議是直接刪掉該頁面。如果真的要做,至少要放到是在同一個(gè)行業(yè)性質(zhì)的網(wǎng)站。
四. 新頁面/更新老頁面內(nèi)容,多久會(huì)被收錄
來自谷歌的John Mueller說,谷歌可能需要“幾個(gè)小時(shí)到幾周”來索引新內(nèi)容或更新內(nèi)容。
也就是說,如果你發(fā)現(xiàn)一天過去了,新頁面還沒有被收錄,不用著急,先按照上面的方法快速檢查一遍。沒有發(fā)現(xiàn)問題的話,就再耐心等等。
那我自己運(yùn)營(yíng)的獨(dú)立站的情況是:新頁面和老頁面的更新,通常被收錄所需時(shí)間在30分鐘到3天。如果新頁面的內(nèi)容主題跟網(wǎng)站的主題相關(guān)度很高、推廣的產(chǎn)品是最近流量和轉(zhuǎn)化非常不錯(cuò)的品類、在過去一段時(shí)間關(guān)于該話題的內(nèi)容也更新得比較頻繁,同時(shí)內(nèi)容質(zhì)量和原創(chuàng)度也高, 那收錄會(huì)非常快,一般半個(gè)小時(shí)就能看到被收錄了。
也有過需要3天左右才被收錄的新頁面,通常發(fā)生在網(wǎng)站新開發(fā)的品類。在這里想特別分享我自己的一個(gè)小心得:以前新頁面超過1天沒有被收錄,我就會(huì)很著急地提交站點(diǎn)地圖,把鏈接分享到外部網(wǎng)站;而現(xiàn)在我是遵循自然收錄原則,不做任何加快收錄的動(dòng)作。這樣做的原因是, 我發(fā)現(xiàn)收錄得慢的網(wǎng)頁,通常在收錄后排名和流量效果都不會(huì)特別理想,因此收錄快慢就能夠作為我去預(yù)判該頁面SEO效果的一個(gè)重要依據(jù)。基于預(yù)判,如果在頁面上線后的半個(gè)月效果不好,那我就會(huì)迅速采取提高內(nèi)容質(zhì)量和布局更多此話題內(nèi)容之類的動(dòng)作,來提升Google SEO排名。
要是新頁面在上線一周后還是沒有被收錄,我認(rèn)為不需要遵守John Mueller所說的標(biāo)準(zhǔn)再等上幾周。除非你的網(wǎng)站或者新頁面的內(nèi)容非常垃圾,否則肯定是哪里出了問題,還是盡早排查為好。
文章為作者獨(dú)立觀點(diǎn),不代表DLZ123立場(chǎng)。如有侵權(quán),請(qǐng)聯(lián)系我們。( 版權(quán)為作者所有,如需轉(zhuǎn)載,請(qǐng)聯(lián)系作者 )

網(wǎng)站運(yùn)營(yíng)至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個(gè)互相交流的平臺(tái)和資源的對(duì)接,特地開通了獨(dú)立站交流群。
群里有不少運(yùn)營(yíng)大神,不時(shí)會(huì)分享一些運(yùn)營(yíng)技巧,更有一些資源收藏愛好者不時(shí)分享一些優(yōu)質(zhì)的學(xué)習(xí)資料。
現(xiàn)在可以掃碼進(jìn)群,備注【加群】。 ( 群完全免費(fèi),不廣告不賣課!)






