Google Bot[1]的工作是在網絡上發現網站、抓取和找到頁面并將其添加到Google的索引中(出現在搜索頁面)。但是網絡空間非常大,Google Bot在抓取任何給定網站時只有有限的時間和資源,所以優化抓取速度很重要。
但從 Gary Illyes 近期的播客上說到,谷歌不會直接 follow 鏈接[2],而是先取鏈接,將它們收集到數據庫中,然后再去逐個檢查它們,如果有了解爬蟲是什么的話,可以再去了解一下爬蟲的工作機制,以及各種爬取比如深度、廣度、權重爬取策略等。
為什么要關注抓取速率?抓取速率直接影響 Google 發現、索引和排名網站內容的速度。
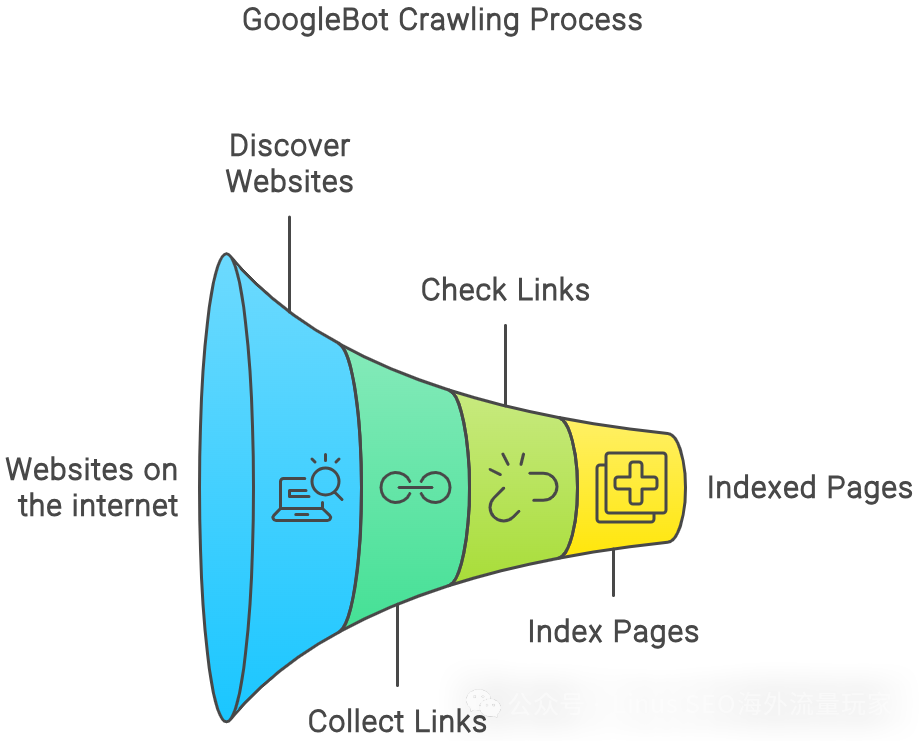
怎么看爬取速率?
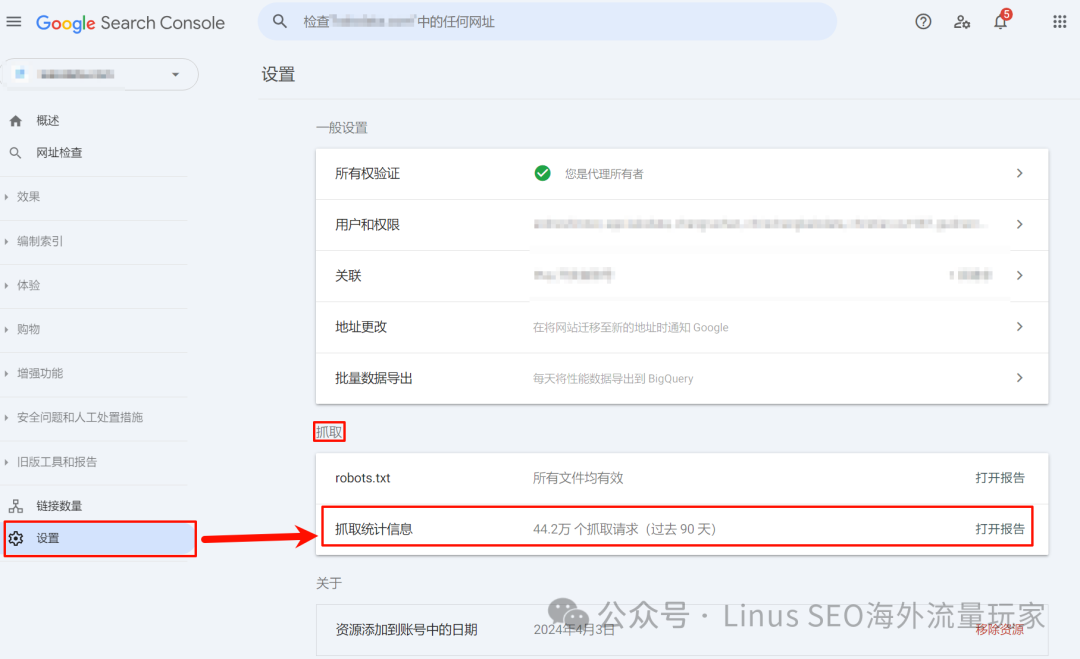
登錄?Google Search Console[3]?即可:
1.?在左側導航菜單中,找到并點擊“設置”(Settings)。
2.?在“設置”頁面上,找到“抓取統計信息”(Crawl Stats)[4]并點擊進入。
怎么優化谷歌爬蟲抓取?
??Robots.txt:這個看?robots 教程[5]就好,它具體會指明理應爬取什么。
??利用 Sitemaps:?站點地圖[6]可以幫助 Googlebot 了解站點的結構和重要頁面的優先級,但一定要注意,站點地圖不能有重復、異常的頁面。除此之外,Priority 也是很重要的,例如,將暢銷產品或新上架產品的優先級設置為高,將庫存較少或即將下架的產品優先級設置為低。Shopify 對 sitemap 做了基礎的分類,這也是一種方式:
??URL 參數:URL參數是附加在網頁地址(URL)后面的查詢字符串,用于傳遞信息或指令給服務器。通常,URL參數以問號?
??開始,參數之間用?&?分隔,比如/page?category=shoes&color=red。如果你用了大量的查詢參數,又沒有指定規范化標簽[7],就會讓谷歌不斷爬取不同參數的 URL,從而造成資源浪費。同樣的,如果你有大量的重復內容,也需要使用 canonical URL。??避免無限爬取:?無限滾動的分頁可能會導致Googlebot浪費資源在抓取不必要的頁面上。這一點你可以看下谷歌的分頁加載規范[8]。當然,以上 2 點有很多人也來用作有意或者無意的蜘蛛陷阱[9](Spider trap)——一種會在網站上陷入無限循環或重復抓取的情況。
-
??監控抓取錯誤:?在抓取統計信息中,會顯示當前的響應情況、信息,可以逐個點擊進入查看。
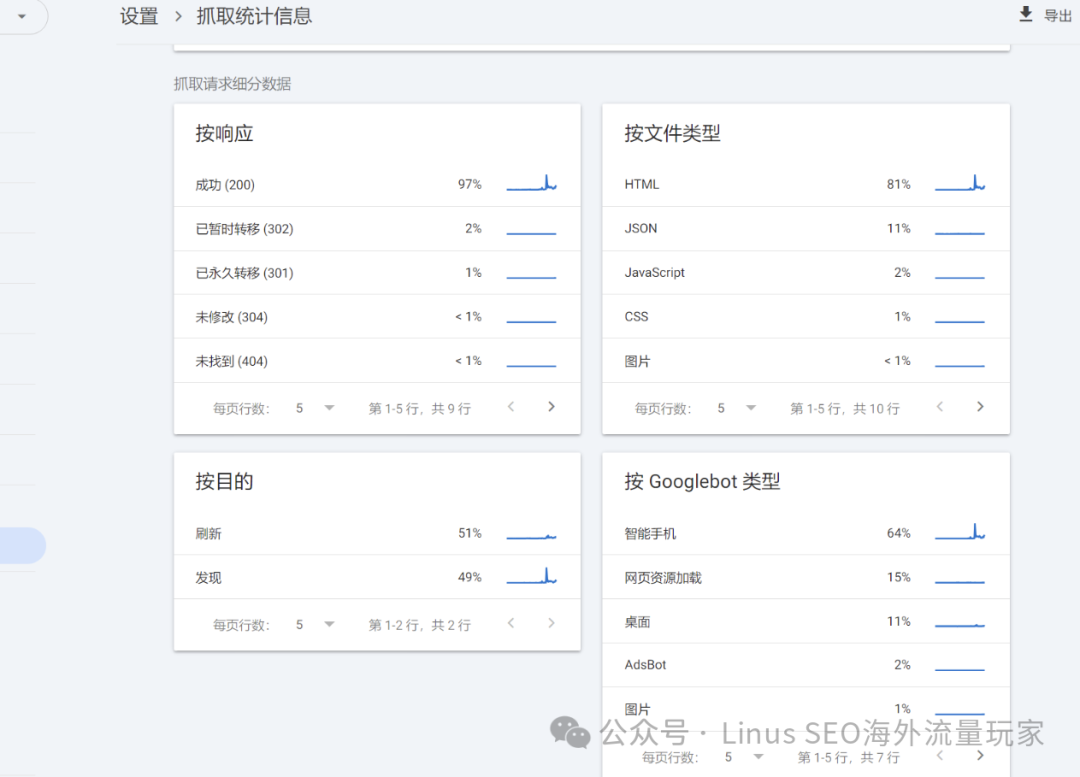
Googlebot爬取頁面的狀態 ??服務器端因素:如果遇到了 DNS問題或服務器阻塞等問題,也會可能產生抓取問題,這是一個坑點,有時會導致網站所有者誤以為問題出在Googlebot上,所以可以先判斷服務器有沒有問題、分析日志的錯誤,是否因為抓取速率或者服務器返回了錯誤。
??If-Amendment-since 頭: 這個 header 可以讓 Googlebot 檢查頁面是否發生了更改,通過比較服務器返回的 Last-Modified 時間與 GoogleBot 本地緩存的頁面時間,而無需再次下載整個內容,從而節省帶寬和資源。
5 個谷歌爬蟲抓取的認知誤區
誤區1. 網站越大,Googlebot 就會抓取越多的頁面。
Googlebot 的抓取是基于算法和優先級的,它會優先抓取重要、高質量、更新頻繁的頁面,而不是簡單地根據網站大小來決定抓取量。
誤區2. 抓取越多,網站權重越高
普遍認為,谷歌機器人(Googlebot)越來越多的爬蟲行為意味著網站質量越來越高。但這種假設具有誤導性,僅僅因為 Googlebot 經常抓取網站并不一定意味著內容是好的。這也可能是由于其他因素,例如:
??被入侵的網站: 如果一個網站被入侵,Googlebot 可能會抓取它更頻繁索引新的網址創建的掛馬中毒頁面、外部惡意鏈接或者無效頁面。
??靜態內容: 如果一個網站一段時間沒有改變,Googlebot 可能會降低其爬行頻率,但并不代表內容不行。
誤區3. Googlebot 只抓取文本內容?
Googlebot 有不同等級的爬蟲,谷歌爬蟲還可以抓取和理解圖片、視頻、JavaScript 等多種類型的內容。但這不代表你就可以隨心所欲用客戶端渲染之類的“現代化”前端操作,必要的 SEO 頁面規范還是要遵循的,靜態化永遠第一。
誤區4. 增加網站內容就會自動提高 Googlebot 的抓取頻率
雖然新內容可能會吸引 Googlebot 更頻繁地訪問網站,但抓取頻率還受到其他因素的影響,如網站質量、更新頻率、服務器性能等。另外,如果你的內容質量不佳(純 AI、無個人見解),也會導致谷歌判定網站權重下降,從而導致抓取速率和頻率下降。
誤區5. 可以通過人工方式強制 Googlebot 更頻繁地抓取網站
有這種方法,但比較灰黑帽 SEO[10],一般不會用,因為對于網站有傷害。實際上,Googlebot 的抓取頻率由算法決定,人工干預通常無效,甚至可能適得其反。還有種說法是,降低抓取頻率可以提高排名,這也是錯誤的,新內容無法被及時索引是非常大的 SEO 問題。
Google Bot谷歌爬蟲的一些FAQs
??要禁止 Googlebot 抓取一些網頁??使用?robots.txt 文件[11],指引各種搜索引擎的爬蟲遵循規范(雖然不一定會遵循)。
??不希望 Google 將某個或者某些網頁編入索引?使用?
noindex,禁止編入索引,并配合?GSC 的刪除頁面功能[12]。??需要完全阻止抓取工具或用戶訪問某個網頁?請使用其他方法,例如密碼保護[13],但從 SEO 角度,請不要使用地區保護方式(比如只限制某個國家地區訪問或 IP 屏蔽),以防 Googlebot 混淆。
??爬蟲爬太快了,壓力太大?Google 會自行確定最佳的網站抓取速度,如果你想要讓抓取速度在短時間內減慢[14],則應向抓取請求返回 500、503 或?429[15]?HTTP 響應狀態代碼(而非 200),如果實在不行,可以提交過度抓取報告[16]來降低爬取速率。
??Googlebot 會判斷性能分數嗎?不會,谷歌使用真實的 Chrome 使用數據來引入有關特定頁面的核心網絡生命周期的數據。其中包括?LCP、FID 和 CLS 分數[17]。Googlebot 抓取并不是 Google 獲取此數據的來源,而是瀏覽器的實際訪問行為。
谷歌爬蟲算是非常基礎且老生常談的話題,Google 官方文檔和各類資料都很齊全,遇到問題就具體情況具體分析。
參考鏈接
[1]?Google Bot:?https://developers.google.com/search/docs/crawling-indexing/googlebot?hl=zh-cn[2]?谷歌不會直接 follow 鏈接:?https://www.seroundtable.com/google-follow-links-37892.html[3]?Google Search Console:?https://search.google.com/search-console[4]?“抓取統計信息”(Crawl Stats):?https://search.google.com/search-console/settings/crawl-stats[5]?robots 教程:?https://developers.google.com/search/docs/crawling-indexing/robots/robots_txt?hl=zh_cn[6]?站點地圖:?https://developers.google.com/search/docs/crawling-indexing/url-structure?hl=zh_cn[7]?規范化標簽:?https://www.semrush.com/blog/canonical-url-guide/[8]?分頁加載規范:?https://developers.google.com/search/docs/specialty/ecommerce/pagination-and-incremental-page-loading?hl=zh-cn[9]?蜘蛛陷阱:?https://yoast.com/spider-trap/[10]?灰黑帽 SEO:?https://seo.yiguotech.com/archives/what-is-white-hat-seo[11]?robots.txt 文件:?https://developers.google.com/search/docs/crawling-indexing/robots/intro?hl=zh-cn[12]?GSC 的刪除頁面功能:?https://search.google.com/search-console/removals[13]?其他方法,例如密碼保護:?https://developers.google.com/search/docs/crawling-indexing/control-what-you-share?hl=zh-cn[14]?讓抓取速度在短時間內減慢:?https://developers.google.com/search/docs/crawling-indexing/reduce-crawl-rate?hl=zh-cn[15]?429:?https://www.webfx.com/web-development/glossary/http-status-codes/what-is-a-429-status-code/[16]?提交過度抓取報告:?https://search.google.com/search-console/googlebot-report?hl=zh-cn[17]?LCP、FID 和 CLS 分數:?https://seo.yiguotech.com/archives/seo-web-core-vital-inp[18]?谷歌搜索中心近期的播客: Crawl smarter, not harder:?https://youtu.be/UTAo-mfM75o[19]?Gary Illyes在Linkedin上的關于GoogleBot的討論:?https://www.linkedin.com/posts/garyillyes_crawling-smarter-not-harder-activity-7228608152844337152-4H2b/
文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)